在现代互联网和企业级应用环境中,数据库的高可用性与数据一致性成为业务持续发展的基石。PostgreSQL作为开源关系型数据库的佼佼者,凭借其丰富的功能和优秀的性能,广受开发者和企业青睐。然而,面对大规模应用和复杂业务场景,单一节点数据库难以满足冗余备份、故障切换以及负载均衡等需求,因此Postgres的集群与复制能力显得尤为重要。近期,EDB公司推出了EDB Postgres Distributed(PGD)解决方案,通过简洁的命令行工具,极大地简化了Postgres集群的创建与维护过程,为用户提供了一个高效且具备云原生特性的分布式数据库方案。本文将围绕PGD的搭建细节,结合具体操作过程,完整介绍如何在AWS环境下部署三个节点的Postgres集群,并实现DDL和DML的逻辑复制,保障数据的实时同步和集群的弹性扩展。首先,准备云端基础设施是成功部署集群的前提。
推荐使用Ubuntu 24.04版本的t3.micro实例,每台配置至少8GB磁盘空间,保证系统与数据库运行的基本需求。将三台实例放置在同一个安全组中,并对安全组的入站规则做出调整,允许组内节点之间的所有TCP连接通信,确保节点间能够顺畅交换数据和状态信息。环境准备完毕后,登陆每台机器,注册获得免费的EDB订阅令牌,该令牌是访问PGD及EDB Postgres Extended安装包的钥匙。通过环境变量导出此令牌后,配置PGD的官方软件源,完成相关软件包的安装。仓库脚本安装后,通过apt-get更新软件包索引并安装edb-pgd及pgextended17等核心组件。采用Postgres用户身份执行接下来的集群初始化命令,降低权限带来的安全隐患,并保证操作环境的一致。
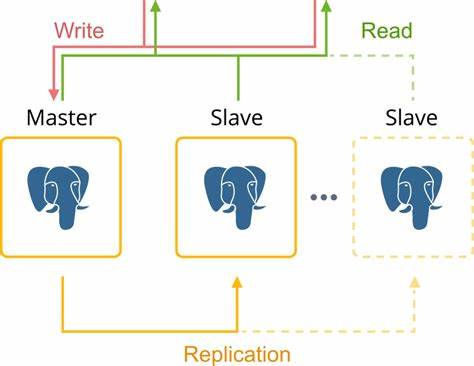
以私有IP地址标记各节点并做环境变量声明,方便后续命令脚本引用。接下来,在第一个节点(NODE0)上执行pgd node setup命令,配置其DSN、监听地址、数据库数据路径以及日志输出位置,并指定集群的初始节点数。完成此基础节点的搭建后,通过pgd nodes list命令能够验证集群状态,显示节点活跃且服务正常。集群健康检查报告中可以看到所有BDR节点均能访问,Raft共识机制运行流畅,复制槽工作正常,同时各节点之间时钟同步无显著漂移,有效避免了因时间差异导致的复制异常。随后,登陆第二、第三节点(NODE1和NODE2),通过类似的setup命令进行配置,唯一不同的是增加cluster-dsn参数,将第一个节点作为集群入口,使新节点能够加入已有集群。在完成三个节点的配置后,集群中的所有节点都会显示为活跃状态,集群拓扑结构形成完整的三节点环。
进入集群体验复制功能是理解PGD价值的直观方式。在第一个节点中创建示例数据表orders,包含客户ID、订单ID及金额三个字段,并插入一百万条随机生成的测试数据。通过分布式逻辑复制,完成的数据和DDL变更会自动同步至其它节点,无需手动干预。验证查询结果显示,三台服务器中orders表的记录数均达到一百万条,表明复制机制能够保证跨节点的数据一致性和完整性。当某个节点出现故障或需要临时退出集群维护时,PGD体现出灵活的节点管理特性。以NODE2为例,执行节点剔除操作后,集群自动调整状态,同时允许运维人员在该节点停止数据库服务并清理数据目录。
重新执行setup命令完成数据重建时,节点能够从集群中其他成员同步缺失数据,确保恢复后与集群保持一致。该过程不仅支持故障恢复也为集群滚动升级提供了思路,利用逐个替换节点、升级版本的方式保证系统无停机、高可靠运行。总体来看,EDB Postgres Distributed为Postgres用户打造了一个简洁高效且易于操作的集群解决方案。通过完善的命令行工具和合理的设计理念,PGD不仅满足了企业对数据复制和节点管理的常规需求,也体现出对云原生架构的深刻理解,具备强大的弹性和自愈能力。对想快速入门Postgres集群和多节点复制的用户而言,按照本文步骤示范搭建的三节点集群足以作为学习和测试的平台,帮助掌握核心技术,同时为生产环境部署奠定基础。未来,随着技术的不断演进,更多优化和功能升级亦将推动Postgres在分布式数据库领域发挥更大作用。
通过本文介绍的集群搭建与复制实践,相信读者能够深入理解Postgres分布式复制方案的操作流程和优势,提升自身数据库架构设计能力,实现系统的高可用和数据安全保障。 。