随着人工智能技术的迅速发展,大型语言模型(LLM)在自然语言处理领域展现了强大的能力。然而,如何实现高效、低延迟且支持大规模并发的推理系统,成为推动这类技术落地和广泛应用的关键。vLLM作为一个开源的高吞吐量LLM推理引擎,以其创新的架构设计和丰富的优化技术,成功应对了多GPU、多节点环境下复杂推理任务的挑战。本文将深度剖析vLLM推理系统的核心组成部分与先进特性,帮助读者全面理解现代LLM推理系统的技术架构与演进思路。 vLLM的设计理念始于构建一个灵活且高性能的引擎核心。该引擎不仅支持标准Transformer模型的推理,还集成了分页注意力机制、连续批处理和动态调度策略等技术手段,极大提升了内存使用效率与计算吞吐率。
在不依赖分布式环境的单GPU离线场景中,vLLM通过细粒度任务调度和高效的KV缓存管理,实现了多请求的并发处理,保证推理效率的最大化。 引擎构造过程中,vLLM配置系统提供了丰富的参数调整选项,用户可以绑定模型信息、缓存设置及并行度策略等。输入处理器将用户原始文本转化为引擎核心请求格式,随后由引擎核心客户端统一管理计算任务,最后输出处理器负责将模型计算结果转换成人类可读的响应。这套体系不仅提高了模块的解耦和扩展能力,也便于后续集成异步或分布式组件。 其中,模型执行器承担着推理的核心计算工作,当前的UniProcExecutor以单GPU单进程模型为基础,支持后续升级为MultiProcExecutor以应对多GPU环境。调度器作为任务管理枢纽,在请求队列管理、优先级策略和KV缓存资源分配等方面发挥核心作用。
KV缓存管理器则是分页注意力机制的心脏,将长序列信息拆分为多个缓存块,极大缓解了显存压力并加快了缓存访问效率,从而支持大规模上下文的推理。 推理流程由请求预处理开始,每个输入都会生成唯一请求ID并配套其元数据。调度器将请求根据不同策略如先到先服务或基于优先权放置于等待队列,随后进入执行队列。引擎的step函数是推理执行的核心循环,按调度、前向计算和后处理三个阶段依次推进任务,可实现连续批处理能力,有效保证推理资源的高利用率和低响应延迟。 分页注意力机制是vLLM独具特色的优化技术。它将传统的KV缓存空间划分为固定大小的缓存块,通过块级索引替代线性存储,显著降低显存占用的同时,支持动态加载和释放缓存块。
这一设计不仅提升了长文本的处理能力,也为分布式缓存系统的设计提供了理论基础。 为了防止少数大请求阻塞调度,vLLM引入了分块预填充(chunked prefill)策略,将长上下文拆分为多个小块分步处理,允许其他请求交替执行,平衡了系统的吞吐和延迟表现。此外,前缀缓存功能通过缓存多个请求共享的共同前缀Token对应的KV缓存,避免了重复计算,有效加速了带有相同引导文本的批量推理场景。 vLLM还集成了引导式解码(Guided Decoding)功能,通过文法有限状态机约束生成过程中的token选择,确保输出符合特定语言规则或格式要求。这一技术在代码生成、模板填充与结构化文本生成领域表现突出,极大提升了生成内容的正确性与实用性。 在提升推理速度方面,vLLM实现了猜测式解码(Speculative Decoding)技术。
该方法引入小型草稿模型快速生成多个候选Token,再由大模型验证和筛选,显著减少了大模型频繁前向计算次数,提升了整体生成速度。vLLM内置的n-gram、EAGLE和Medusa三种高效猜测方案各具特点,适应不同业务需求,保障了加速效果和采样质量的平衡。 应对大模型对显存需求的增长,vLLM从UniprocExecutor逐步过渡到MultiProcExecutor。后者支持多GPU并行计算,内部采用进程级通信与调度,实现了张量并行和管线并行等技术,允许加载数十亿参数规模甚至更大模型。多进程架构确保资源协调和负载均衡,同时对外接口保持一致,便于开发者无缝扩展硬件资源。 在分布式服务层面,vLLM通过API服务器与多节点引擎协作构建了完整的推理服务架构。
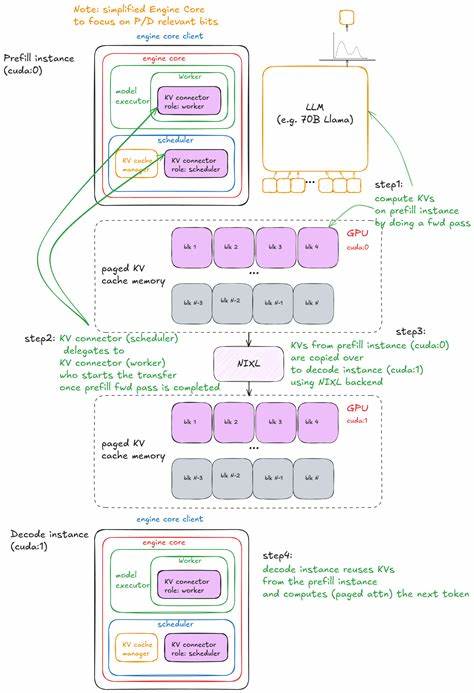
后端引擎进程通过ZeroMQ异步通信和NCCL数据并行库紧密协作,实现数据分片和多副本负载均衡。前端采用基于FastAPI和Uvicorn的异步框架,承载HTTP请求接口,保证高并发环境下的稳定响应和可扩展性。 vLLM同时支持预填充与解码任务的分离部署,将资源消耗较大的预填充请求和对响应延迟敏感的解码请求分别发送至不同节点,有效避免长尾任务影响整体吞吐。结合KV缓存服务进行信息共享,为多阶段推理提供高效支撑,显著优化了时间到首字(TTF)和生成间隔(ITL)等关键性能指标。 性能监控和自动调优是vLLM推理系统的另一个亮点。系统内置了多种基准测试工具,涵盖延迟测量、吞吐量评估和端到端性能分析。
通过模拟真实工作负载,可获得精确的服务能力指标。基于这些数据,自动调优脚本能调整批大小、调度策略和资源分配,确保部署环境下的SLOs被满足,最大化硬件投资回报。 总结来看,vLLM以其模块化的引擎架构、创新的缓存管理方案和灵活的分布式服务框架,成为当下高性能大型语言模型推理的代表系统。它不仅针对Transformer标准架构进行了深度优化,还为异构模型和多样化硬件平台提供了良好的扩展接口。随着业务场景对实时性和大规模并发性能需求的不断提升,vLLM的设计思想和技术实现具备较强的引领性和参考价值。 未来,随着多模态模型、稀疏专家网络以及更复杂解码策略的出现,vLLM生态与内核还将持续升级,进一步推动大型语言模型在工业界和学术界的广泛应用。
深入理解vLLM的系统构成和性能优化路径,对研发者、运维人员乃至产品经理而言,都具有重要的实践意义和指导价值。通过不断创新和优化,真正实现智能语言模型的高效可靠服务,为更多智能应用场景赋能。 。