在现代数据库管理系统中,查询优化器扮演着关键角色,其使命是为每条SQL查询选择最优的执行计划,从而尽可能高效地完成查询任务。然而,优化器所选的计划真的总是最优的吗?这个问题看似简单,却充满复杂性和实际应用中的不确定因素。本文将系统性地分析查询计划的优化频率及其背后的技术挑战,帮助读者全面了解查询优化的现状和未来发展趋势。 查询优化器基于成本估算来做出计划选择,成本通常源自选择性估算以及基本资源的消耗,如磁盘I/O、CPU时间等。选择性估算是指优化器对查询条件筛选出的数据比例的预估。精准的估算直接关系到计划的好坏,但遗憾的是,优化器在实际运行中经常会犯错,导致选出的计划并非真正的最快方案。
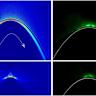
以一个简单的SELECT查询带范围条件为例,不同的扫描方法(如索引扫描、位图扫描、全表扫描)在不同数据分布和查询选择性下表现迥异。实际测试数据显示,当查询匹配的数据占表的1%到5%时,优化器倾向于选择索引扫描,但该选择往往表现不佳,执行时间比简单的顺序扫描长很多。此现象警示开发者,盲目追求索引扫描并非提高性能的万能钥匙。 进一步观察位图扫描的表现可以发现,在低选择性场景下,位图扫描常常胜出,甚至以大约十倍的优势强于索引扫描。位图扫描之所以表现优越,部分原因在于它支持预读机制,而传统的索引扫描不具备此功能。预读允许系统提前加载相关页面,减轻了等待磁盘I/O的瓶颈。
值得注意的是,以上测试主要针对均匀分布的数据集,这种分布带来了最差的数据局部性,且优化器假设数据的统一分布和列间独立性。在更为复杂真实的数据分布中,查询计划的选择变得更加棘手。例如,在带有周期性摆动和随机扰动的数据集上,优化器偶尔会错误切换扫描策略,体现出对复杂统计理解的局限性。在线性且无扰动的数据中,优化器表现最为理想,能稳定选择最快方案,因为数据规律性强且适合操作系统的读预处理机制。 硬件环境的不同也对计划选择有重要影响。现代的NVMe固态硬盘配合高速处理器如Ryzen 9900X能够缩小不同扫描方法间的性能差距,而在传统SATA SSD或机械硬盘环境下,差异更为明显。
此外,缓存状态对性能表现有显著作用——当数据缓存在页面缓存或共享缓冲区时,优劣差异会大幅减小,甚至消失,因为数据访问瓶颈从磁盘I/O转向内存访问。 优化器只能基于有限的统计信息进行决策,这些统计数据是对真实数据的高度压缩和简化,忽略了许多复杂的相关性和分布细节。虽然通过增强统计信息并引入更多关联统计可以部分改善估算精度,但由于统计收集过程本身也有开销和技术难题,数据库系统很难做到完全动态和详尽的统计覆盖,必然引入估算误差。 此外,成本模型的准确性对计划选择同样至关重要。当前成本模型往往是对硬件资源消耗的粗略模拟,随着云计算环境中存储和计算资源架构变得复杂多变,这些模型的误差可能被进一步放大。硬件层的缓存机制、多租户资源调度、虚拟化开销等因素均难以准确建模,增加了优化器决策的难度。
尽管存在许多挑战,基于成本的查询优化仍然是目前最有效的方案。相比于硬编码规则或简单启发式方法,成本模型具有适应性和灵活性。但为提高查询计划的健壮性,数据库未来的发展方向可能包括动态调整执行计划的能力,当执行发现计划并非最优时,进行实时调整,从而缩小性能上的巨大落差。 用户在实践中应围绕优化器行为建立合理预期,理解并非每个查询都是最优执行,同时关注选择性变化处的性能“断崖”,这是查询计划切换的典型特征。合理设计索引、选择合适的统计信息采集策略,以及适时手动干预计划选择,都能带来性能上的提升。 总之,查询计划的最优性受到多方面因素的制约,包括数据分布、硬件环境、缓存状态、统计信息的完备程度及成本模型的精准度。
虽然优化器目标是选择最快计划,但现实中往往难以完全实现。未来对查询优化的改进既依赖算法和统计技术的进步,也需要结合实时执行反馈机制,不断缩小理论与实践之间的差距。理解并合理利用现有优化机制,将是数据库应用性能优化的关键所在。