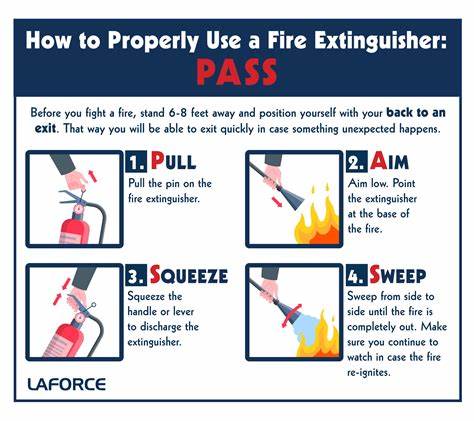
在边缘计算与物联网快速普及的今天,越来越多的开发者试图把AI模型部署到价格低廉、体积小巧的树莓派上。树莓派因其开放生态、丰富的外设接口和强大的社区支持,成为嵌入式AI实验和原型开发的第一选择。然而,把复杂的神经网络"放进"有限的内存和算力中并不是一件容易的事。本文面向想要在树莓派上实现AI推理的工程师与爱好者,系统分析常见障碍并提供可落地的优化策略与工具链建议。 首先要明确树莓派的硬件边界。无论是经典的树莓派3,还是性能更强的树莓派4/4B,或者内置更大内存的后续版本,都会受到CPU主频、缓存容量、可用RAM、热设计与I/O带宽的限制。
树莓派通常缺乏强大的浮点计算单元和大规模并行矩阵乘法能力,这使得直接在设备上运行大型Transformer或大尺度卷积神经网络难以为继。了解这些局限,能帮助开发者在架构选择和资源分配上做出明智决定。 选择合适的模型架构是第一要务。为树莓派优化的网络通常以轻量级为目标,包括MobileNet系列、EfficientNet-lite、ShuffleNet和SqueezeNet等。TinyML方向的模型、经过知识蒸馏的精简版网络,以及剪枝后的小型自定义模型,都能在保持可接受的精度前提下显著降低计算量与内存占用。对于需要文本处理的场景,TinyBERT和DistilBERT等压缩模型比原始大型Transformer更现实。
模型量化与剪枝是常用且高效的优化手段。通过8位整数量化或更激进的混合精度量化,可以将模型体积压缩数倍,并在许多视觉任务中实现几乎无损的精度。结构剪枝和非结构化剪枝能进一步减少不必要的权重,但剪枝后一般需要微调以恢复精度。配合知识蒸馏,将大模型的"软标签"传递给小模型,能在保持泛化能力的同时提升推理效率。 合理选择推理框架能显著简化部署复杂度并提升性能。TensorFlow Lite以轻量化和丰富的硬件后端支持著称,适合大多数树莓派项目。
PyTorch Mobile与ONNX Runtime也逐渐完善,对开发者友好。对于使用Intel Movidius或Google Coral等外部加速器的场景,分别可借助OpenVINO和EdgeTPU编译工具链实现最佳推理性能。选择框架时,应关注模型格式转换的兼容性、量化支持、以及是否能利用硬件加速器。 硬件加速器为树莓派带来实质性改进。Google Coral USB加速器内置Edge TPU,适合运行量化后的卷积神经网络,能在低功耗下实现高帧率的视觉推理。Intel Neural Compute Stick以Movidius芯片为核心,兼容OpenVINO生态,适合批量推理任务。
还有基于PCIe或USB的NPU、FPGA外设可选。集成时需考虑驱动兼容性、电源供应与热管理,确保外设与树莓派的I/O和供电能力匹配。 内存管理与存储策略也直接影响推理稳定性。将模型尽量存放在快速存储介质上,避免频繁的I/O阻塞。对于内存受限的系统,使用内存映射文件(mmap)或分段加载模型参数可降低瞬时内存峰值。合理配置交换空间虽然能缓解短时OOM问题,但频繁的磁盘交换会严重拖慢推理速度并缩短存储介质寿命。
尽可能增加物理内存或采用更小的模型才是根本解决方案。 性能调优需要系统视角。单纯提升CPU频率或启用多线程并不总是线性带来性能增长,因为缓存一致性、热节流和内存带宽瓶颈都会限制实际效果。使用性能剖析工具监测推理的瓶颈所在,比如CPU占用、内存带宽、线程调度开销或I/O等待。通过分离预处理和推理线程、避免不必要的数据拷贝、使用张量内存对齐和批处理策略,可以在同等硬件下大幅提升吞吐量与延迟稳定性。 热管理在持续推理场景中尤为重要。
树莓派在长时间高负荷运行时会出现温度升高并触发降频,导致推理速度下降。使用合适的散热片、风扇或外壳设计,甚至可以考虑外接主动散热模块。也可以在软件层做频率调度,平衡延迟与功耗,针对低延迟需求采取短时高频策略,而对于背景任务采用更低频率以降低温度和能耗。 部署时要考量应用场景和用户体验。视觉监控、语音唤醒、本地语音识别、边缘预测与机器人控制是树莓派常见应用。对实时性要求高的控制系统,应优先保证推理的确定性和低抖动;对数据隐私和离线可用性有要求的项目,本地化推理能避免敏感数据外发。
设计时应权衡模型复杂度与用户体验,可能需要在精度和延迟之间做出妥协。 数据管道与预处理不可忽视。在设备上进行高效图像预处理、音频采样和特征提取可以显著降低输入数据对网络的负担。尽量将预处理操作以原生C/C++或加速库实现,避免Python解释器的开销成为瓶颈。对视觉任务可使用硬件摄像头的裁剪与缩放功能减小数据传输与处理量。 安全性和可靠性在边缘部署中具有长期价值。
确保模型文件与推理服务的完整性,使用安全启动或签名验证可以防止被替换或注入恶意模型。对外设数据进行权限控制与加密,避免未授权访问。定期备份配置与模型版本,并实现安全的远程升级机制,既能修补漏洞又能在模型迭代中保持服务连续性。 调试与监控是长期维护的核心。建立推理性能的日志记录体系,监控延迟、帧率、内存占用和错误率,对发现瓶颈和异常行为至关重要。采用轻量级的遥测方案可以在不显著增加负载的前提下收集关键指标。
在开发阶段,应通过单元测试与回归测试保证模型更新不会带来意外性能退化。 对于资源极其受限的应用,考虑将部分计算卸载到局域网内的更强设备或云端。边云协同模式可以在保障低延迟的同时,支持复杂模型的推理和大规模数据分析。设计时要平衡网络不稳定时的退化策略,确保设备在离线状态下仍能提供基本功能。 展望未来,专门针对边缘设备的NPU、微控制器级别的AI加速器和更高效的模型架构将进一步降低在树莓派类设备上部署AI的门槛。TinyML生态的成熟、模型压缩技术的进步以及自动化的模型搜索工具将帮助开发者用更少的资源完成更多任务。
与此同时,开源社区和硬件厂商的协作会带来更多兼容性强、易部署的工具链。 总之,把AI模型"困"在树莓派里并非不可行,关键在于正确评估硬件边界、选择适合的轻量化模型、采用量化与剪枝等优化手段、结合合适的推理框架和硬件加速器,并注重热管理、内存与存储策略以及长期的监控与安全维护。通过系统性的优化与工程实践,树莓派可以成为边缘智能应用的可靠平台,不仅适合原型验证,也能在许多实际场景中承担起低成本、高效能的推理任务。 。