随着数据流处理的广泛应用和技术迅猛发展,构建高性能流处理平台成为业界关注的焦点。面对海量数据和复杂计算需求,存储层的选择极大地影响整体系统的性能和可扩展性。RocksDB作为知名的嵌入式键值数据库,以其成熟的设计和广泛应用被许多项目视为理想存储引擎。然而,针对高性能流处理平台,RocksDB却暴露出一系列难以克服的技术瓶颈,令开发者不得不另辟蹊径。本文将聚焦RocksDB在流处理平台中的实际表现,揭秘其在性能扩展、零拷贝机制支持、配置复杂性及测试效率等多方面的短板,佐以实践案例,阐述为何定制存储引擎是更合适的选择。流处理平台的数据结构复杂,且数据量通常巨大,需要对内存中的状态进行持久化以及不适合内存存储的大型数据结构进行溢写。
以Feldera为代表的流处理系统,其核心数据结构Z-set不仅支持带权重的行元素存储,同时需要高效的迭代、合并与键查找操作。由于Z-set与RocksDB底层的LSM-Tree架构有一定的类似性,最初团队选择RocksDB来避免重新造轮子。这种选择看似合理:RocksDB支持多列族管理不同索引,拥有丰富的API接口,且作为成熟项目,其代码质量及稳定性得到社区认可。同时Rust语言的RocksDB客户端实现提供了定制化比较器以及零拷贝获取的潜力,使之成为技术选型的热门。然而,在实践中,RocksDB面临多线程扩展困境极大限制流计算平台的并发吞吐能力。Feldera团队通过将每个索引放置在不同列族以避免线程间同步,仍发现性能严重受限于软件层面锁竞争。
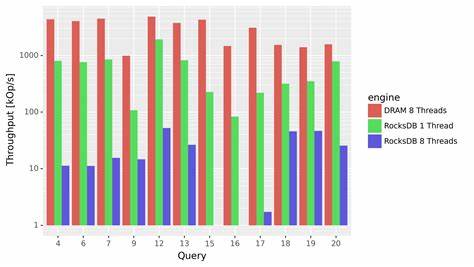
实际测试数据表明,单线程条件下RocksDB处理百万级事件仍表现良好,但当并发线程增加至八个时,其处理吞吐量急剧下滑至仅数百事件每秒。值得注意的是,这种性能下降并非由硬件瓶颈如SSD I/O能力不足导致,而是显著来自于RocksDB内部的写入日志锁争用。这一现象说明其底层设计对于大规模并发数据写入支持不足,与现代流计算需要海量并行处理的特性背道而驰。除扩展性问题,反复的序列化与反序列化操作成为性能杀手。RocksDB以字节切片形式存储数据,键值匹配需将数据反序列成语言层对象,而实测表明这一过程产生大量内存分配与释放开销,导致CPU资源大量浪费。特别是对需要自定义比较函数的应用来说,每次寻址操作均需反复反序列化键,从而严重拖慢响应时间。
尽管Rust中诸如rkyv这种零拷贝反序列化库提供了理论上消除这部分开销的潜力,但RocksDB对字节切片的对齐不充分以及其基于C++实现的内存布局不可控,使零拷贝操作在实际运行中经常触发非预期的panic,中断程序稳定性。这一兼容性障碍进一步削弱了其性能优化空间。此外,RocksDB复杂的配置项成为另一大难题。面对成百上千的参数选择,非专业人士难以掌握最佳调优方案。即使进行了诸如启用BlobDB等优化尝试,提升幅度也仅约20%。为解决此困境,学界亦不得不借助人工智能辅助模型来推荐配置,侧面反映其高门槛与复杂性。
这种过度设计和臃肿的选项对于专注于流计算业务逻辑的开发团队来说无疑增加了负担。测试过程中,使用大量列族进一步暴露了RocksDB的性能缺陷。Feldera的测试体系依赖大量属性测试,导致上千个短生命周期列族频繁创建,显著拖慢测试速度,使测试时间从数分钟暴涨至半小时。该问题作为RocksDB自2019年以来的已知遗留缺陷,尚未获得有效修复,影响了开发效率。综上所述,虽然RocksDB在传统键值存储场景中表现优异,具备稳定性和成熟的生态,但其在高性能、多线程流平台环境中遇到的瓶颈不容忽视。针对这些问题,Feldera团队选择开发自定义存储引擎,以更好地满足分区无共享架构的并发要求,实现真正的零拷贝反序列化和类型安全优化,从根本上改进数据访问效率和系统可扩展性。
未来博客中,Feldera将分享其存储层设计细节,展现如何通过简化架构和深度集成零拷贝技术提升流处理平台性能。总体来看,选择存储引擎时,唯有精准匹配业务特点和底层架构需求,方能获得持久可靠的性能保障。存储引擎不是百搭配件,而是决定流处理平台能否突破性能天花板的关键利器。开发者和架构师应警惕一味依赖通用方案而忽略潜在缺陷,积极探索适合自身场景的定制化路径。在快速演进的数据技术浪潮中,唯有深入理解核心痛点,才能打造真正高效、稳定及可扩展的流计算系统,驱动数据价值最大化。