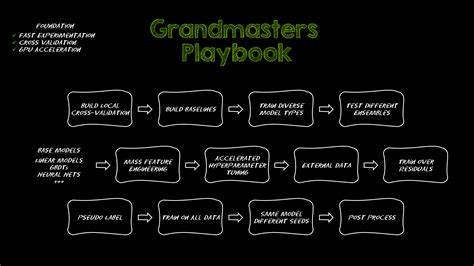
在数据科学领域,表格数据是最常见的数据类型,但却往往是最具挑战性的。如何从复杂庞大的表格数据中挖掘有效信息,建立准确且稳健的预测模型,一直是机器学习竞赛和实际项目中的关键所在。Kaggle作为全球最大的数据科学竞赛平台,其冠军团队不断探索和验证出一系列切实可行的技巧与方法,形成了堪称业界经典的"Kaggle Grandmasters Playbook",尤其对于表格数据建模,提供了七大战斗验证的技巧。这些技巧不仅适用于竞赛中追求精度的团队,也为工业界处理大规模、多样性数据提供了宝贵经验。 快速实验与严谨验证是成功的基石。 无论是竞赛还是企业项目,快速实验的能力决定了发现数据特征和模型表现核心规律的效率。
通过高质量、多轮次的实验,团队能够快速捕捉模型中的不足、过拟合或数据漂移的风险,及时调整方案提升效果。实现这一目标的关键在于优化整个数据处理、特征工程、模型训练及评估流程,并不仅仅是加速模型训练阶段。 GPU加速技术在这一过程中发挥了巨大作用。通过利用GPU加速的pandas替代品如cuDF,数据预处理和特征构造可以实现秒级响应;训练时则可选用GPU版本的XGBoost、LightGBM、CatBoost等梯度提升决策树算法,以及GPU加速的cuML库,实现大规模数据和复杂模型的快速迭代。 同时,验证策略的科学设计不可忽视。采用k折交叉验证而非单次划分,可以更全面地评估模型泛化能力。
针对数据特性选择合适的验证方法,如时间序列数据应用TimeSeriesSplit,带分组结构的数据则使用GroupKFold,能有效防止训练测试集分布差异对评估带来的误导。 深度探索数据,远超基本EDA。 传统的数据探索多集中于缺失值统计、异常点检测、相关性分析与简单分布观察,虽然是基础但远远不够。Kaggle大师们强调,深度了解训练和测试集的差异,是预防模型在生产环境中失效的关键。通过对训练与测试特征分布的比较,识别潜在的分布漂移,避免模型在验证时表现良好但上线后效果下滑。此外,目标变量的时间序列趋势、周期性和季节性需要重点关注,这类模式在数据中隐含复杂信号,若不加区分地训练模型,难以保证在未来数据上的稳定表现。
例如,在亚马逊KDD Cup竞赛中,详细分析发现训练与测试数据存在显著分布差异,并且目标变量随时间展现出加速增长和明显季节波动。基于该发现,团队采用了匹配的时间序列验证方法并进行了专门的特征处理,最终奠定了夺冠基础。 构筑多样化快速基线,开启模型全景。 许多从业者仅仅搭建一个甚至一组固定模型作为基线,检查性能好坏便止步,但这远远不足以支撑系统的优化。更科学的做法是尽快建立多种类型的基线模型,涵盖线性模型、梯度提升树、小型神经网络等,形成对数据表现的全方位认知。 这种多样化基线不仅构建了最低性能门槛,还能暴露数据特征、模型适配度和潜在的问题。
例如基线模型的退步可能提示数据泄漏、异常或者严重偏差。对比不同模型类别的表现有助于确定后续重点方向,避免盲目投入资源在效果明显不佳的算法上。 在一个预测降雨量的竞赛中,基线阶段便涵盖了梯度提升树、神经网络和支持向量回归,即便无复杂特征处理,也达成了极具竞争力的成绩,展示了多样基线设计的重要性。通过GPU加速训练,能够在极短时间内完成大规模模型的对比和验证,大大加快探索节奏。 丰富特征构造,深掘数据潜力。 表格数据领域,特征工程依然是提升模型性能的核心武器。
现实中,单靠原始特征往往难以捕获复杂关系,创造新的衍生变量是唤醒隐藏信息的关键。单纯依赖CPU和pandas在大规模特征工程面前计算耗时极高,限制了实验次数和广度。 利用GPU加速技术,工程师能够在数日内生成数千甚至数万特征,例如通过组合多个类别特征创造新的交叉特征,揭示不同维度间的复杂联系。这不仅可以显著提高模型的感知能力,也能带来对细节模式的捕捉。 在多个Kaggle竞赛和实战项目中,通过大规模特征工程夺冠的案例屡见不鲜。GPU加速同样使得特征编码、聚合、归一化等预处理步骤变得高效且流畅,为连续迭代打下坚实基础。
巧妙融合多模型,挖掘组合优势。 单一模型虽然可以表现优异,但不同算法间通常具备互补优势。通过模型融合,能够提升整体预测的稳定性和准确率。Kaggle大师们偏爱两种融合手段:爬山算法(hill climbing)和堆叠学习(stacking)来实现这一目标。 爬山算法通过逐步调整不同模型权重,保留在验证集表现提升时的组合,迭代至无明显增益。此方法自动且高效,借助GPU的向量计算能力,可以快速评估成千上万个组合方案,远远超越传统CPU的执行效率,极大提高融合效果。
堆叠学习则进一步强调使用另一层模型,通过学习基模型输出的误差和预测结果,实现更复杂的组合规律捕捉。多层堆叠策略能够融合不同模型捕获的线性与非线性特征,适合存在显著多样性模型的场景。虽然训练成本高昂,但GPU加速大幅缩短计算时间,让多层堆叠成为可行的策略。 凭借上述融合策略,在Podcast听众时长预测竞赛中,复杂三层堆叠模型帮助团队夺冠,再次证明融合的强大威力。 用伪标签扩充数据,提升泛化能力。 伪标签技术通过利用训练好模型对未标注数据生成预测标签,进而将这些数据纳入训练中,实现数据集的扩充和模型对未知分布的适应能力提升。
这种方法类似于知识蒸馏,学生模型在接收教师模型软标签的引导下,能更好地捕获数据中的信号和规律。 有效的伪标签策略强调多轮迭代和软标签的应用,避免简单硬标签引入噪音,并结合交叉验证严格控制信息泄露风险。此外,可以使用伪标签对有标签数据中的噪声样本进行筛选处理,进一步净化训练数据。 由于伪标签通常需要多次训练和预测循环,计算成本极高,GPU加速的训练与推理能力显得尤为关键,使得多轮伪标签策略在合理时间内得以实现。在BirdCLEF物种分类挑战中,采用多轮伪标签显著提升了模型对新物种和不同音频条件下的泛化。 多次重新训练,充分利用全部信息。
即使在获得优秀模型之后,进一步利用不同随机种子多次训练,并对全量数据重新拟合最终模型,也能带来额外提升。不同的随机初始化帮助模型突破局部最优,增加预测的多样性并通过集成获得更稳健的结果。 强大的GPU计算力使重复训练成本大幅下降,原本需要几天甚至更长时间的多模型训练,可压缩到数小时完成,极大提升了整个建模流程的灵活性和精度。 总结来看,Kaggle大赛冠军们总结的方法体系,打破了表格数据建模慢、复杂、难以量化的传统印象,通过GPU加速和科学流程管理,实现了快速探索、严谨验证和多模型融合的高度整合。这不仅帮助他们在全球竞赛中屡获佳绩,也为数据科学社区带来了切实可行的实战指导。未来,随着硬件性能和算法优化持续进步,这套方法论将继续推动表格数据建模迈向新高度,帮助更多从业者实现数据价值最大化。
。