近年来,随着人工智能技术的迅猛发展,大型语言模型(LLMs)在代码生成领域展现出了惊人的能力,Python、JavaScript、Java等主流编程语言的代码生成正确率和实用性逐渐提高。然而,当面对q/kdb+这类独特的编程语言时,LLMs却难以胜任,这背后的原因不仅仅是数据量的匮乏,更关键的是q/kdb+代码的“从右向左,无优先级”的评估顺序导致模型在理解与生成时频频出错。 q/kdb+语言起源于APL及其后代语言k和J家族,遵循的原则明显不同于以往编程语言的传统运算规则。大多数现代编程语言都采用自左向右、有操作符优先级的解析方式。例如Python中表达式0.5 * y + x / (2 * y)的计算顺序清晰,运算符的优先级保证了除法在加法之前进行处理,使得代码易读且符合普遍化编程习惯。 然而,在q/kdb+中,表达式同样的写法却被解析为(0.5 * y) + x % 2 * y,按照从右向左、无优先级的规则执行,这种操作顺序看似反直觉,但却是该语言设计的核心。
APL语言创始人、图灵奖得主Ken Iverson曾强调,从右向左评估使表达式更便于从左向右阅读,同时对非结合函数的定义更具表现力和实用价值。这样的设计满足了为多维数据处理和高性能分析而生的q/kdb+需求。 大型语言模型虽然在训练中具备对自然语言和多种代码语法的学习能力,但对于这类从右向左无操作符优先级的规则,却往往生成介于q语法和其他语言间的混淆代码,无法准确把握括号位置和运算顺序,造成生成代码的语法错误和逻辑不正确。例如,Claude模型在实现牛顿迭代法时,错误地将表达式写作Python样式的0.5 * y + x / (2 * y),而非q/kdb+应有的(0.5 * y) + x % 2 * y,导致算法实现偏差。 这种现象不仅仅是模型对q语言不足认知的简单体现,更反映出神经网络模型对时间序列顺序的理解与生成存在固有限制。模型常基于自左向右生成文本的方式进行训练,而q代码需要逆向的时间序列思考,即先考虑代码的右部,再推导左部内容。
这种反向生成和阅读的需求与当前主流模型的结构相悖。 与此类似,右向左的自然语言书写体系(如阿拉伯语、希伯来语)与q/kdb+代码的区别在于,前者仅在视觉呈现层面使用右向左排序,而生成过程仍是顺序的。相比之下,q/kdb+在语义层面上的“逆序”逻辑需要模型从语法和逻辑本质改变对代码的处理方式。甚至有趣的是,在某些编码工具或LLM交互界面中,缺乏对从右向左显示的支持,会导致字符顺序出现奇怪的断裂或混乱,影响用户体验和代码编辑。 为了解决上述挑战,研究者和开发者们尝试引入“中介层”概念,类似于自然语言翻译中通过界面层实现视觉从右向左展示一样,这个中介层将q/kdb+的原生代码转换为一种更适合LLM理解的形式,从而绕过模型直写q语言时的障碍。具体来说,开发了类似“Qython”这样的Python风格中间语言,LLM能够依托其熟悉的左向右语法,将所需逻辑用Qython表达,随后通过自动化转换工具将Qython代码精准编译成符号及顺序均符合q/kdb+规范的原生代码。
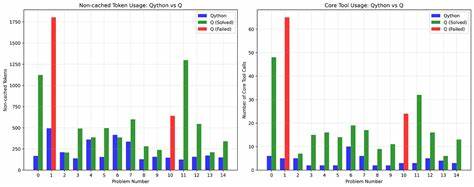
Qython的核心优势在于它维持了Python语法的简洁与通用性,同时通过编译器的转换,保证了q语言特有的右向左、无优先级操作的执行逻辑。借助Qython,LLMs在无需根本改变模型架构的前提下,能有效避开直接编写q代码时陷入的歧义与错误,比起直接靠模型理解和生成原生q语言更具实用价值。 然而,Qython仍处于初级发展阶段,词汇量和语法映射的覆盖范围有限。更为复杂的q语言特性,尤其是基于输入数据类型变化的大量运算符重载,需要进一步完善转换器和语言分析工具。同时,逆向翻译,即从q/kdb+代码解析回Qython,对于语法动态性高、缺乏统一公文档的q语言而言,是更为复杂的任务。当前思路是结合AST抽象语法树解析与智能推断,通过多模型协作完成精确转换。
从市场角度看,q/kdb+语言用户群体相对小众,使得为此大量训练和优化LLM变得缺乏经济吸引力。这意味着大型通用模型在短期内难以针对q语言进行专门训练或调优,使得现阶段通过架设中介层、翻译层以及专门工具链的方案成为更现实的路径。与此同时,社区内的开发者也在不断推进q语言专用的AI辅助工具,包括集成开发环境插件、代码自动生成和调试助手,以缓解人工实现q语言代码时的高门槛。 随着数据科学和金融行业对q/kdb+的依赖日益增强,如何提高编程效率和降低入门难度成为行业关注点。未来,可能会有更多专门面向q语言的语言模型涌现,甚至可能诞生采用逆序编码及生成的新型神经网络架构,专门支撑这类特殊语言的语法和语义处理。此外,结合链式思维(chain-of-thought)技术,模型或许能更好地模拟从右向左的逻辑流程,进而逐渐缩小当前存在的性能差距。
总的来说,q/kdb+语言独特的设计理念和执行顺序,对当前主流大型语言模型提出了较大挑战,反映了AI技术在面对少数复杂编程语言时的局限性。通过设计专门的中间语言和转换工具,结合未来潜在的模型结构创新,有望打破壁垒,实现高效、准确的q语言代码生成与辅助。当前的尝试和技术路线也为其他少数民族语言或结构独特的编程体系提供了宝贵的经验和思考启示。未来在AI与编程语言的融合道路上,这种针对性与灵活性的提升将成为关键。