近年来,大型语言模型(LLMs)因其强大的自然语言理解和生成能力引起了广泛关注,但它们庞大的规模和对计算资源的高需求也成为限制其广泛应用的瓶颈。相较之下,小型语言模型(SLMs)因其体积小、效率高及更易于部署的特性,逐渐成为业界关注的焦点。微软最新推出的Phi-3系列小型语言模型正是这一领域的突破性产品,凭借创新的数据训练方式和卓越的性能,被业界誉为"小而强大"的人工智能利器。 Phi-3系列由微软研究团队打造,当前已公开发布Phi-3-mini版本,参数规模仅为3.8亿,却在多项语言、编程和数学能力相关的基准测试中超越了体积更大甚至是参数翻倍的其他模型。这一成绩的取得,源于微软对训练数据选择和处理过程的颠覆性创新。研究人员通过从儿童语言学习的启示出发,设计出以高质量数据为核心的训练集,极大提升了小型模型的理解和生成能力。
微软研究员Ronen Eldan在一次陪伴女儿读故事书的过程中产生了灵感,他思考一个四岁儿童是如何通过有限的词汇学习并理解语言的。团队以此理念出发,打造了"TinyStories"数据集,通过人工智能生成数百万篇简短的儿童故事,涵盖了高频名词、动词和形容词的搭配。小型语言模型在该数据集上的训练令其能够流畅生成语法正确、富有逻辑的故事内容,彰显了高质量数据对模型性能的关键影响。 在此基础上,微软进一步扩展了训练数据集,集成了大量经过精心筛选的公开教育类文献,构建了更加完善的"CodeTextbook"数据体系。通过反复过滤和AI辅助内容合成,使得训练数据不仅丰富且质量极高,有效降低了模型出现错误或不当回答的风险。这样的训练方法不仅揭示了小模型利用高质量数据超越尺寸瓶颈的可能,也为未来小型AI模型的发展指明了方向。
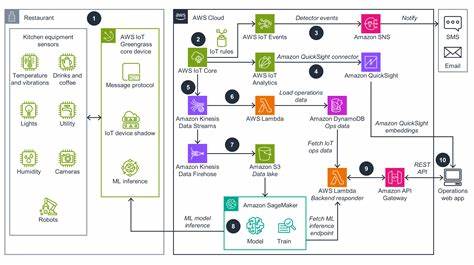
Phi-3系列模型被整合进微软Azure AI模型目录,以及主要的机器学习平台如Hugging Face和Ollama,同时也可通过NVIDIA NIM微服务接口部署在多种环境中。这种便捷的部署方式极大地降低了企业和开发者的使用门槛,无需依赖云端服务器就能实现本地运行,这对于网络连接不稳定或对数据隐私有高要求的行业具有特殊价值。 边缘计算和本地AI推理是当前产业热点,许多应用场景如智能交通、工业传感器、远程环境监测、无人驾驶汽车等都期望摆脱对云端的依赖,提升响应速度并增强数据安全性。Phi-3模型低延迟且可脱机运行的特性,使其非常适合这些应用环境,更加普惠地推广人工智能技术到全球各个角落,尤其是偏远或网络条件有限的地区。 微软相关负责人表示,小型模型并非要取代大型语言模型,而是要构建一种多样化的模型组合架构。不同任务的复杂度和资源条件决定了选择适合的模型。
例如,简单的文档摘要、市场分析、文本生成或客户服务自动化,Phi-3能够高效胜任;而涉及复杂推理、跨领域知识整合的任务,则仍需调用大型模型来完成。微软内部已开始将大型模型作为智能路由中心,根据用户请求的需求智能分发至相应规模的模型,实现资源的最优配置。 在安全和道德层面,微软同样严肃对待Phi-3模型的风险管理问题。开发团队采取多层次的测试和人工红队审查机制,确保模型在实际应用中尽可能避免生成不当或有害内容。此外,Azure AI生态提供了多种工具,帮助开发者构建更安全、更可靠的应用程序,保障用户体验和数据安全。 Phi-3小型语言模型的发布标志着人工智能模型发展的新阶段 - - 不仅仅是追求更大、更复杂的模型,更注重质的提升和适用性的优化。
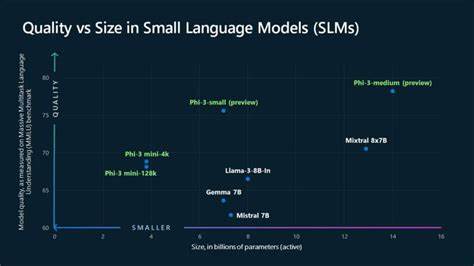
通过深挖数据的"价值密度",小模型也能实现令人惊艳的自然语言处理能力。随着更多型号如Phi-3-small(70亿参数)和Phi-3-medium(140亿参数)陆续投放市场,用户将拥有更多选择,能够根据实际需求和资源状况灵活选型,实现更广泛的AI赋能。 这一系列创新成果不仅展现了微软在AI基础研究领域的领先实力,也为全球AI行业提供了宝贵的示范。随着小型语言模型技术的成熟,未来我们可以期待更加智能、高效且绿色的AI应用广泛渗透于教育、医疗、制造、金融等各个行业,推动社会数字化转型和智能升级迈上新台阶。 同时,小型语言模型对开发者社区和普通用户而言,也是一大福音。低门槛的本地化AI推理能力,让数以亿计的智能设备焕发新活力,助力开发者打造更多贴近用户需求的创新产品,真正实现"让AI走进千家万户"的愿景。
未来,随着硬件性能的提升和算法不断优化,Phi-3及其后续小型模型还有望带来更多意想不到的惊喜和突破。 概括来说,Phi-3小型语言模型通过以儿童语言学习为灵感、注重数据质量和精细训练,成功打造出一种兼具实力与灵活性的AI解决方案。它不仅突破了大模型在人力和资源上的限制,也为AI的普及和安全使用奠定了坚实基础。随着这一技术的不断成熟与推广,人工智能将在更广泛的领域发挥巨大潜力,改变人们的生活和工作方式,为数字时代注入更多无限可能。 。