大型语言模型(LLM)技术的迅猛发展正在重塑人工智能的应用格局,从自动客服到复杂信息处理,AI代理的能力日益强大。然而,伴随着这些智能代理的普及,针对它们的安全威胁也日渐突出,其中提示注入攻击作为一种新兴且极具隐蔽性的漏洞,正对AI系统的可靠性构成严重挑战。提示注入攻击指的是攻击者通过向模型输入中注入恶意指令,诱导模型执行其原本不应执行的行为,进而造成信息泄露、功能误用甚至系统崩溃。为此,设计安全稳健的LLM代理,防范此类攻击,成为业界关注的热点。 在理解防御策略之前,必须先了解提示注入攻击的工作原理。大型语言模型依赖输入提示(prompt)进行任务执行,攻击者利用提示中的灵活文本特征,将恶意命令隐藏在自然语言中。
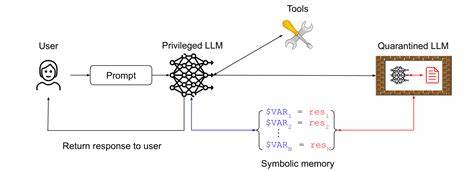
当模型针对这些输入做出响应时,往往会无意间执行攻击者植入的命令。尤其当模型连接外部工具或访问敏感数据时,风险进一步扩大。针对此威胁,研究者提出了多种设计模式与安全原则,旨在提升模型对潜在注入的抵抗力,同时兼顾实用性与用户体验。 设计模式是软件开发中经过总结和验证的解决方案,在AI安全领域同样适用。针对LLM代理,安全设计模式强调输入验证、输出过滤、上下文隔离、权限控制等核心机制。具体而言,输入验证确保只有符合预定格式或合法范围的提示能够被模型接受,有效阻断噪声与恶意文本的渗透。
输出过滤则对模型生成的响应进行检测与清理,防止泄露敏感信息或执行异常操作。此外,上下文隔离技术确保任务环境彼此独立,攻击者难以利用跨任务依赖实现侧信道攻击。权限控制则严格限制代理访问外部资源的能力,最大限度降低攻击面。 在实际部署中,这些设计模式往往需要组合使用。多层防御策略可有效弥补单一机制的不足,提升系统整体安全性。比如,在输入端实施严格的语义分析与结构化校验,结合运行时监控和动态异常检测,形成闭环防护体系。
同时,采用模型内置或外部工具辅助的自动化审计和日志管理,增强攻击溯源能力,为安全事件响应提供支持。 此外,对设计模式的安全性和实用性权衡尤为关键。过度限制可能影响模型的灵活性和响应质量,而宽松策略则易被攻击利用。针对这一挑战,一些研究提出可证明安全性的设计框架,通过数学与理论分析验证防御效果,实现安全和效能的平衡升级。实际案例表明,结合密码学方法、可信执行环境及多因素身份验证,有助于构建高度可信赖的AI代理系统。 具体案例也为设计模式的应用提供了宝贵参考。
例如,在某金融领域智能助理系统中,通过细化用户输入角色区分、构建提示模板白名单以及限制查询权限,成功防止了多起尝试越权访问关键交易信息的提示注入企图。在医疗问诊机器人项目中,则结合了多源数据融合和上下文语义隔离,确保患者隐私不被意外泄露。 未来,随着LLM技术不断进化,提示注入攻击手法也将趋于多样和智能化。为应对这一趋势,研究者倡导开放的安全设计生态,鼓励跨学科合作与持续迭代优化。开源安全工具链和动态防御系统的开发有助于提升整个行业的防护水平。同时,加大对AI模型安全教育与意识的普及,强化开发者和用户对潜在风险的认识亦必不可少。
总之,面对大规模推广的智能代理安全挑战,设计模式为构建防范提示注入攻击的坚固屏障提供了理论基础和实践指引。通过系统化的安全架构和技术手段,结合具体应用场景需求,能够有效保障LLM代理的安全运行与数据隐私。未来的成功关键在于不断创新防护机制,完善政策法规支持,形成技术与治理并重的安全生态体系,推动大型语言模型智能代理迈向更加安全可信的里程碑。