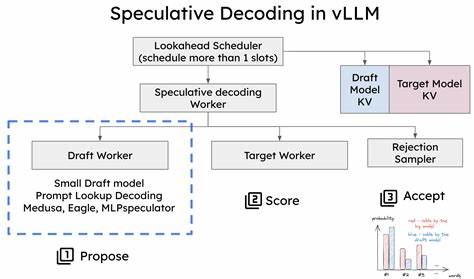
随着人工智能和自然语言处理技术的飞速发展,大规模语言模型(LLM)在各类应用中扮演着越来越重要的角色。然而,伴随模型规模的不断扩大和多样化的应用需求,推理阶段的计算瓶颈愈发明显。尤其是在处理异构词汇表时,传统的解码方法面临着显著的效率和准确性挑战。为此,快速推测解码算法(Fast Speculative Decoding Algorithms)应运而生,成为提升语言模型推理性能的关键技术之一。 所谓异构词汇表,指的是在文本生成过程中涉及多种不同类型和来源的词汇集合,这些词汇在语义、结构甚至编码方式上可能存在较大差异。传统解码算法大多假设词汇表均匀且同质,难以适应词汇多样性所带来的复杂性,导致推理速度受限,且容易出现解码误差。
快速推测解码算法针对这一痛点,通过创新性的设计和优化策略,实现对异构词汇表的高效支持,兼顾速度与准确性。 快速推测解码的核心思想基于推测生成的策略,意图在保证最终输出质量的前提下,通过预测后续可能的词汇序列,提前完成部分计算过程,从而减少模型的计算时长。在面对异构词汇表时,该算法能够智能区分不同词汇类型,利用各自的特点优化推测过程。具体而言,它将解码分为多个阶段,先以较粗粒度的预测覆盖大范围词汇,再在确认阶段细化选词,这种层次化的推测机制有效避免了全词表搜索的高昂代价。 此外,快速推测解码算法通过引入损失无损(lossless)策略,确保推测过程不会牺牲模型的最终输出质量。这一点对于实际应用至关重要,特别是在对生成文本准确性要求极高的场景中,如法律文件起草、医药信息生成等。
该算法通过严格的验证和回退机制,能够及时纠正推测过程中可能出现的错误,从而实现性能和可靠性的双重提升。 从技术实现层面来看,快速推测解码算法融合了多项先进技术手段。首先,它采用了高效的并行计算架构,充分利用现代计算硬件的多核优势,加快推断速度。其次,算法设计中巧妙融合了神经网络的概率分布预测与传统搜索策略,形成高效的混合解码方案。此外,为适应异构词汇表,算法引入了动态词汇表管理机制,能够根据上下文和任务特性调整词汇访问优先级,增强解码的灵活性和适应性。 该算法不仅在学术研究中获得广泛关注,也在工业界展现出强大的应用潜力。
诸多领先技术公司已开始将快速推测解码算法集成到其自然语言处理系统中,用以优化聊天机器人、智能客服、内容生成平台等多个领域的性能。例如,通过显著缩短响应时间,提升用户交互体验;在内容生成方面,提高生成速度的同时保证文本的连贯性和准确度;在多语言混合环境下,实现流畅且高效的跨语言对话。 未来,快速推测解码算法仍有广阔的优化空间和发展前景。随着模型规模的继续扩大以及多模态融合技术的发展,解码算法需要进一步提升处理复杂、多样输入的能力。同时,结合自适应学习机制,使算法能够根据实际应用反馈动态调整策略,将成为提高推理效率和模型智能水平的重要方向。研究者还在探索将该算法应用于更广泛的任务场景,如实时翻译、多语言自动摘要、复杂逻辑推理等,期待为智能系统带来更高效、更精准的语言理解与生成能力。
总结来看,快速推测解码算法针对异构词汇表的处理难题,以创新的推测机制和损失无损保障,显著提升了大规模语言模型的推理速度和准确性。这不仅为当前的自然语言处理技术注入了强劲动力,也铺就了未来智能语言服务进一步发展的坚实基础。在全球人工智能应用需求不断增长的背景下,该算法有望成为提升智能系统性能的重要利器,推动自然语言处理迈向更加高效、智能的新阶段。