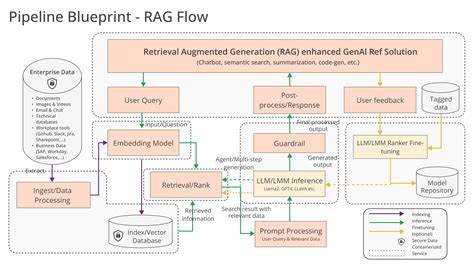
随着人工智能技术的飞速发展,检索增强生成(Retrieval-Augmented Generation,简称RAG)成为提升自然语言处理应用质量的关键手段。RAG通过结合强大的检索机制和生成式大型语言模型(LLM),帮助用户快速、准确地获得所需信息。这其中,Vespa作为领先的分布式搜索引擎,凭借其强大的检索和排名能力,为构建高性能的RAG应用提供了坚实基础。本文将深入解析RAG蓝图,系统介绍如何利用Vespa构建一套高效且可扩展的RAG系统,包括数据建模、检索策略配置、分阶段排序设计、模型训练与应用部署等方面,为开发者提供实用的技术指导和最佳实践。 在构建RAG应用时,选择合适的数据建模方案至关重要。RAG蓝图推荐以“文档”为基本的搜索单元,结合自动分块技术将文档文本分割为固定长度的文本块,每个文本块独立嵌入向量并索引。
此策略既保持了上下文的完整性,又有效避免过细粒度带来的数据冗余和性能瓶颈。文档中除文本内容外,结构化的元数据和信号字段同样不可忽视,这些包含创建时间、修改时间、用户行为信号(如打开次数、收藏状态)等信息,在检索和排序阶段可作为重要的辅助特征提升排序质量。 针对文本和向量信息的高效检索,RAG蓝图采取了混合检索策略,即结合传统的文本匹配和语义向量相似度搜索。文本匹配使用强大的BM25算法,具备计算效率高、广泛适用的优势;而向量检索则通过近邻搜索捕获语义层面的相关性,弥补文本匹配无法覆盖的语义空白。Vespa通过支持多字段、多算子联合检索,允许用户灵活组合不同维度的检索手段,实现检索召回率和精准度的双重提升。举例而言,在检索阶段同时对文档标题的词级嵌入和文本块的块级嵌入执行近邻搜索,并与文本的弱AND查询联合过滤,获得更全面的候选文档集。
在向量嵌入的选择上,蓝图强调根据应用场景权衡模型的维度大小、推理效率及召回质量。Vespa支持多种精度的向量表示,其中二进制向量(以int8格式存储)能够显著压缩存储和提升计算效率,适合作为匹配阶段的召回向量。对于排序阶段则推荐将二进制向量解包为浮点表示,结合查询向量计算更为精确的余弦相似度分数。此外,Vespa原生支持如ColBERT的多向量嵌入以及Matryoshka嵌入策略,为不同的应用需求提供更多选择。 建立搜索架构时,合理划分分布式应用包结构及查询配置可大幅提升开发和运维效率。RAG蓝图提倡将模型文件、模式定义、查询配置及排名策略划分为独立模块,便于多版本迭代及针对不同业务需求进行定制。
查询配置文件中通过查询配置集成统一嵌入函数及YQL检索语句,同时提供多套查询模板(如基线混合查询、深度调研查询、RAG生成查询)满足多场景调用需求。 排名设计是RAG系统质量提升的核心环节。蓝图采用了Vespa的分阶段排序机制,落地先快速过滤的第一阶段排序以及高质量细粒度排序的第二阶段。第一阶段排序使用轻量级的线性组合模型,涵盖BM25分值、最大和平均语义相似度等特征,以保证召回文档的相关性和效率。排名模型参数基于实际数据通过特征采集脚本和PyVespa客户端进行训练,确保模型权重反映真实检索场景与用户需求。 第二阶段排序允许接入更复杂的基于机器学习的模型,例如LightGBM或XGBoost梯度提升树,通过对丰富的文本特征、嵌入特征及元数据特征进行综合利用,大幅提升排序精确度。
训练过程中实现5折交叉验证和早停机制,避免过拟合,同时通过特征重要性分析优化特征组合。训练完成的模型导出为JSON格式,完整集成至Vespa应用,方便分布式部署和在线推断。 除了传统的检索和排序机制,RAG蓝图强调了LLM生成模块的无缝对接。Vespa支持本地部署的模型或基于OpenAI接口的远程调用,灵活适配不同的应用环境和数据保密需求。在API配置层面,可通过云端密钥管理安全传递OpenAI密钥,实现生产环境安全调用。同时,对于查询端请求,RAG蓝图推荐采用在查询链中集成LLM组件,通过流式传输格式(如SSE)实时返回生成结果,提升交互体验。
在实际部署和评估环节,蓝图利用PyVespa提供的多种评估工具,实现对检索召回率、查询延迟、排名准确率(包括Precision、Recall、NDCG等指标)的系统监控和持续反馈。通过设定多组检索方案对比(纯语义、纯文本、混合),协助调整匹配算子参数及嵌入维度大小。在排序效果评估中,针对第一阶段和第二阶段模型分别进行评测,以确保整体性能达到预期。 RAG蓝图不仅为初学者提供了具体的技术路线,还强调了系统可扩展性和实用性。其设计充分考虑了生产环境的扩展需求,支持容器化部署,可独立扩大内容节点或查询节点,灵活应对数据增长和用户查询峰值。通过分模块管理排名配置和查询模板,支持多种用例共存和不断迭代优化,保证系统具备良好的通用性和适应性。
未来,RAG蓝图还提出了多阶段全球排序(Global-phase Ranking)和更深度的用户反馈闭环构想。通过引入跨编码器模型或进一步提升的GBDT模型,实现对第二阶段结果的再排序,提升最终文档排序的可解释性和准确度。在收集更多用户交互数据和引入LLM自动评注的帮助下,可以不断丰富训练样本,提升模型的泛化能力和鲁棒性。 总的来说,RAG蓝图为构建高质量智能检索系统提供了系统化、可落地的参考架构。它结合了语义理解与传统文本检索优势,通过先进的分阶段排名和机器学习模型,显著提升信息检索的准确性和效率。与此同时,蓝图注重系统的灵活性和可扩展性,便于应用在各种规模和领域的实际场景中。
对希望打造符合现代AI需求的大规模检索增强生成应用的开发者而言,深入理解和应用RAG蓝图无疑是打开成功之门的重要钥匙。