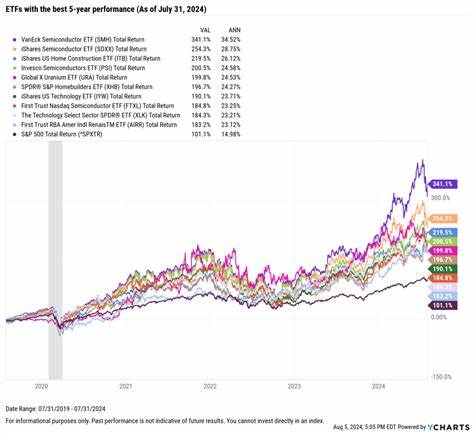
人工智能技术的飞速发展催生了越来越多功能强大的智能体,这些智能体在面对复杂的现实环境时展现出令人瞩目的能力。与此同时,确保对智能体性能的科学评估变得尤为关键,这不仅有助于客观比较不同模型的优劣,也为持续优化算法提供准确的方向。智能体基准(Agentic Benchmarks)作为这一评估体系的核心,承载着对智能体进行测评的重任。然而,当前不少智能体基准在设计和执行过程中存在一定的问题,影响了评估结果的准确性和可比性。因此,建立严谨的智能体基准构建最佳实践显得迫在眉睫。近年来,诸多研究者针对智能体基准的构建提出了深入的分析与方法论,旨在提升基准的科学性和实用价值。
基准测试的核心目标是通过明确的任务定义和合理的奖励设计,客观反映智能体在特定场景下的表现。以往的研究表明,部分基准在测试用例数量有限或评价准则不合理的情况下,容易导致对智能体能力的高估或低估。例如,某些基准因测试案例覆盖面不足,未能充分体现智能体处理多样任务的能力,而另一些基准则可能因评价标准包含误导性指标如空回应计为成功,导致数据失真。面对上述挑战,研究团队提出了智能体基准检查清单(Agentic Benchmark Checklist,简称ABC),覆盖任务设计、测试用例挑选、奖励机制设定等多个维度,确保基准评测的全面性与公正性。通过在复杂的基准体系中采用ABC,不仅优化了测试流程,还有效降低了性能评估中的系统性偏差。例如,在CVE-Bench这样复杂评价设计的基准中,应用ABC成功减少了约三分之一的性能过度估计。
这一成果证明,系统化的基准构建方法能显著提升评价结果的可信度。构建高质量的智能体基准还必须考虑任务的多样性和现实相关性。真实世界场景往往具有复杂性和动态性,智能体在面对多变环境时的表现更能反映其实用价值。因此,基准应纳入多层次、多场景的综合任务,确保评估覆盖智能体的广泛能力。此外,奖励设计作为衡量智能体表现的核心指标,需保持科学性和客观性。奖励函数过于简化可能忽视任务细节,导致智能体策略偏离实际需求,进而失去对真实能力的精准衡量。
与此同时,开放数据和透明评测体系是提升基准公正性的关键。开放共享测试数据和评价标准,能够促进跨团队、跨领域的验证与改进,防止局限于单一场景或标准导致的评价偏差,推动人工智能研究的健康发展。未来,基准测试还应与新兴的评估技术结合,如自动化测试用例生成、动态任务流设计以及多维度评估指标整合,进一步丰富和完善智能体的能力评价体系。随着智能体技术不断走向成熟,建立科学严谨的基准测试体系不仅是推动技术进步的保障,也关乎人工智能最终应用的安全性和可靠性。通过不断优化基准设计和执行标准,科研和工业界能够更清晰地把握智能体的发展现状和潜力,为智能体在各类复杂任务中的广泛应用奠定坚实基础。综上所述,构建严谨的智能体基准是一项系统性工程,涵盖任务多样性、奖励设计、数据开放与评价透明等多个方面。
智能体基准检查清单提供了有效的框架,有助于规避常见设计缺陷,提升评估质量。未来,结合创新评估技术和实践经验,智能体基准必将成为衡量智能体能力不可或缺的基石,驱动人工智能领域迈向更加真实和可靠的发展阶段。