随着人工智能技术的飞速发展,大规模语言模型(LLM)的训练逐渐成为推动自然语言处理进步的核心基石。然而,许多团队在专注于模型架构设计和超参数调优的同时,往往忽略了影响训练效率的基础设施配置,尤其是网络与存储的选择。合理优化网络带宽与存储性能,可以显著缩短训练时间,降低云端资源成本,提升整体研发效率。本文将围绕云端LLM训练过程中的网络和存储瓶颈展开深度解析,结合最新的性能基准测试数据,系统讲解如何通过选择合适的硬件资源,加速模型训练并实现成本优化。传统观念认为GPU算力是训练的主要瓶颈,然而现代高速GPU如NVIDIA H200已远超数据处理需求,真正的障碍在于如何高速、稳定地为GPU供给训练数据。若数据加载及模型参数同步的带宽不足,GPU便会陷入等待状态,计算资源被大量浪费。
通俗地说,GPU就像流水线中的核心加工设备,处理速度极快;但如果输送原料的传送带跟不上速度,流水线整体效率大幅下降。尽管GPU计算能力呈指数级提升,相关的内存带宽和网络带宽提升依然较为有限,这使得网络通信和存储I/O成为分布式训练的性能瓶颈。基于此,优化网络和存储配置成为提升LLM训练效率的关键。云端GPU集群环境下,网络和存储是用户可以直接调控的两大要素。网络决定了训练节点间梯度同步和参数更新的速度;存储则影响了数据加载和模型检查点的读写速度。正确匹配网络与存储配置,是最大化GPU利用率、降低训练等待时间的有效手段。
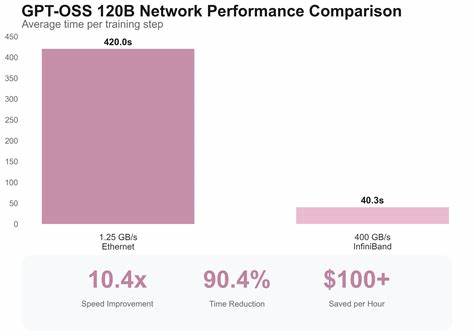
通过SkyPilot和Nebius云GPU平台的联合测试,实际测评了不同网络和存储配置对Gemma 3 12B及GPT-OSS-120B模型训练性能的影响。结果显示,高性能InfiniBand网络相比常见10Gbps以太网带来约10倍训练速度提升。具体来说,单步训练时间从以太网的近40秒缩短至4.4秒,总训练时间可从53分钟降至仅7分钟。该网络加速效果在体量更大的GPT-OSS-120B模型中表现尤为显著,带来同等比例的性能提升。InfiniBand技术支持多达400Gbps的吞吐率,极大减小了节点间通信瓶颈,尤其是反向传播阶段梯度的传输时间大幅下降。相比之下,普通以太网环境中由于带宽限制,ReduceScatter等梯度同步操作成为性能负担。
此外,存储系统的选择同样关键。测试中对比了本地NVMe、Nebius共享文件系统及不同模式的对象存储(包括直连挂载和带缓存挂载)在模型加载、批量数据读取和检查点写入上的表现。虽然本地NVMe以其超过10GB/s的读写速度占优势,适合用于临时文件和中间检查点,但其不可持久性限制了长期保存的应用。Nebius共享文件系统在持久性和性能间取得较好平衡,读写速度分别可达6.4GB/s和1.6GB/s,适合于最终检查点的保存与模型权重加载。而通过对象存储直接挂载的数据读取延迟大幅增加,批量加载时间接近73秒,显著拖慢训练进程。引入缓存挂载模式后,虽然写入速度提升至300MB/s,批量读取时间缩短,但仍不及共享文件系统表现。
针对不同训练阶段,合理分配存储资源能发挥最大效益。批量数据采样阶段采用Nebius共享文件系统保证快速访问,模型加载阶段建议采用对象存储直连挂载以节省存储成本,而检查点保存阶段选择缓存挂载的对象存储实现速度与耐久性的均衡。结合网络和存储的优化策略,整体训练效率提升可达6至7倍。换言之,针对Gemma 12B的80个训练步骤,采用标准10Gbps以太网和S3存储方案的训练耗时为基线,优化至InfiniBand网络及缓存挂载对象存储后,训练时间大幅缩短,显著降低了硬件使用的实际成本。此外,在云端构建高性能训练环境时,实际配置往往繁琐,涉及多种网络参数调优及环境变量设置。SkyPilot平台通过yaml配置文件中简单的network_tier参数,将网络自动升级至InfiniBand,大幅降低用户门槛。
同时对存储通过disk_tier及file_mounts字段进行灵活资源分配,极大提升配置便捷性。此外,不可忽视的是软件层面框架的调试复杂度。大规模分布式训练涉及多层框架堆栈,从高层用户友好但抽象较深的工具,到可控性强但门槛高的底层组件。面对复杂报错和不同硬件资源的兼容性时,理解各层框架间的联动及限制,对于最大化训练性能同样关键。总结来看,云端大规模语言模型训练效率的提升需多维度协同优化。网络带宽和存储I/O是影响GPU利用率的核心瓶颈,通过选择高性能InfiniBand网络及合理混合存储策略,可实现训练时长的大幅缩减及成本优化。
工具级平台如SkyPilot的引入简化了复杂基础设施配置,帮助开发者快速搭建高效的分布式训练环境。未来,随着技术的进步,网络通信技术的进一步提升以及智能存储解决方案的普及,将为云端大规模模型训练带来更大突破。对于构建领先AI能力的企业和研究机构而言,深入理解并精准调优网络与存储资源已成为不可或缺的关键环节。以此为突破口,形成从硬件选型到软件调度的全方位优化体系,将助力下一代语言模型快速迭代,推动人工智能领域迈向更高峰。 。