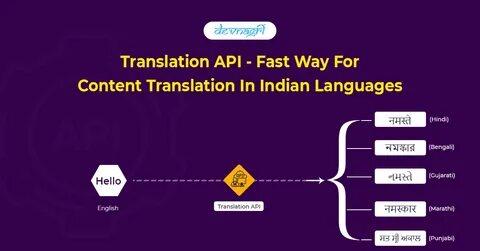
近年来,数字化时代对跨语言沟通的需求愈发强烈,特别是在多语种丰富的国家如印度。印度拥有超过20种官方认可的语言,其文化、教育、法律及公共服务领域的信息传递亟需高效且精准的翻译工具。为此,Sarvam-Translate应运而生,作为一个开放权重(open-weights)且专门针对印度语种设计的神经机器翻译模型,它不仅支持22种印度语言之间的翻译,还极大地提升了对长篇、结构化文本的处理能力。 Sarvam-Translate基于Gemma3-4B-IT模型,通过大规模精细调优训练打造,涵盖了印地语、孟加拉语、马拉地语、泰卢固语、泰米尔语、古吉拉特语、乌尔都语、卡纳达语、奥里亚语、马拉雅拉姆语、旁遮普语、阿萨姆语、迈蒂利语、桑塔利语、克什米尔语、尼泊尔语、信德语、多格里语、孔卡尼语、曼尼普里语、博多语、梵语等22种印度官方语言。该模型不仅能够实现句子和段落级的翻译,还能有效处理带有丰富格式信息的结构化文档,为各行各业的多语言内容本地化提供强大支持。 在技术实现层面,模型针对多样化语料进行了广泛的训练,涵盖科学文献、历史资料、社交媒体内容、法律文书、网页HTML、代码注释、学术论文中的LaTeX公式、化学方程式等多种复杂且具有挑战性的文档类型。
尤其在保留源文档结构和语义一致性的同时,Sarvam-Translate能智能识别并维护诸如HTML标签、代码语法、数学及化学公式等不可翻译的元素,确保翻译结果不仅准确且形式完整。这一能力使得模型在实际应用中减少了人工处理和格式修正的工作量,大幅提升了效率。 除此之外,Sarvam-Translate特别重视翻译的自然流畅性及文化语境的传达。印度语言内部有大量成语、俚语和文化特有表达,传统直译往往难以传神,导致信息丢失或误解。Sarvam-Translate通过丰富的训练语料和高级语言建模策略,能够准确捕捉并转换这些隐含的文化意义。例如,将英文短语“behind the eight ball”在泰卢固语中译为“很麻烦”的对应表达,成功再现了原文的语气和情境。
这对于新闻报道、文学作品、民间故事以及社交平台内容的有效传播尤为重要。 从用户体验角度看,Sarvam-Translate提供了丰富的使用途径。用户可以通过Hugging Face平台免费下载模型权重,在自己的应用系统内当作基础底层进行集成和开发。同时,官方API平台支持在线调用,方便开发者快速试验和部署。基于模型的开放性,开发社区积极参与改进与优化,共同推动印度本地语言技术生态的繁荣与自主可控发展。 在人类评测方面,Sarvam-Translate表现尤为抢眼。
权威语言专家团队进行了严格的翻译质量对比测试,覆盖包括Gemma3-27B-IT、Llama4 Scout以及Llama-3.1-405B-FP8等多款先进模型。结果显示,Sarvam-Translate在多数语言上的译文流畅性、准确性、格式保真度及文化包容性均显著优于其他模型。尤其在15种语言的结构化文档翻译评分中,其准确率超过4.9分(满分5分),体现出优秀的技术实力和应用潜力。 然而,Sarvam-Translate并非没有局限。部分低资源语言如博多语、多格里语、克什米尔语、桑塔利语、曼尼普里语、信德语、梵语等,翻译质量相较其他语言仍有提升空间。此外,对于超长的LaTeX文档或HTML文件,模型在少数情况下会遗漏标签或格式元素,建议使用者将大型文件分割成多个小段进行翻译以确保最佳效果。
同时,少数输出偶现拼音化或夹杂混合语言的情况,需结合具体应用加以监控和后处理。 Sarvam-Translate的优势不仅体现在技术细节,更赋能了教育、科研、政府及商业等多个领域。教育机构能够利用该模型快速实现教科书和学术资源的多语言传播,弥合语言鸿沟。政府单位可借助高质量翻译推广公共政策和服务,确保信息惠及各族群体。企业则能提升面向印度各地市场的内容本地化水平,增强文化亲和力及客户体验。Web开发者借助对HTML结构的智能识别及保护,在多语种网站建设中避免因格式错乱引发的显示问题。
未来,Sarvam-Translate将持续更新优化,逐步扩展支持范围和应用场景。随着印度数字生态的快速发展,跨语种沟通需求愈加多样且复杂,该模型的开放策略促进了学术界与产业界的协同创新。通过搭建共享平台和开放社区,更多技术人才得以参与到印度语言技术的探索中,共同推动拥有独立自主版权和高性能表现的印度语言AI技术体系建设。 数字化时代的语言壁垒正在逐渐被打破,而Sarvam-Translate正是赋能这场革命的重要力量。凭借其强大的多语言处理能力、高度还原结构化信息和丰富的人文关怀,Sarvam-Translate不仅仅是一个翻译工具,更是连接不同文化、促进信息平等的桥梁。未来,这款模型将助力印度语言实现真正的数字主权,推动普惠教育、社会包容和经济增长,成为推动印度信息化进步不可或缺的数字基石。
。