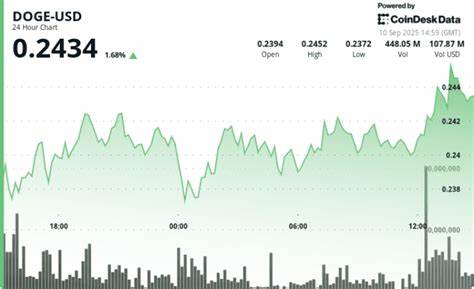
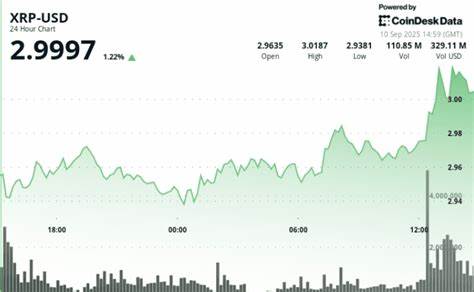
在现代互联网技术飞速发展的背景下,网络数据成为推动业务和科技创新的重要资源。面对庞杂且动态变化的网页信息,开发者和数据分析师亟需高效、稳定的数据抓取工具,Web Fetch工具正是在此需求下应运而生。它通过程序化访问网页,实现对网络内容的自动化捕获和处理,极大地提升了数据收集的效率与质量。Web Fetch工具的核心价值不仅在于抓取网页数据,更在于其能够针对不同网页格式和技术栈灵活适配,满足多样化场景需求。随着网络技术的多元化发展,传统的抓取方式逐渐暴露出效率低下、适应性差以及易被网站防护机制阻拦的缺点。Web Fetch工具结合先进的抓取策略和智能规则,优化了请求频率和数据提取逻辑,使得数据抓取过程更加智能化与精准化。
Web Fetch工具的设计理念强调模块化与扩展性,其通常包含请求管理模块、内容解析模块和数据存储模块。请求管理模块负责模拟浏览器行为,处理请求头信息、Cookie及重定向等细节,保证访问的合法性和有效性。内容解析模块运用DOM解析技术、XPath、正则表达式等手段,从结构化或非结构化的网页中提取目标数据。数据存储模块则将抓取的数据按照需求存储到数据库、本地文件或通过API传递给其他系统,支持后续分析与处理。在实际应用中,Web Fetch工具被广泛运用于电商价格监控、舆情分析、市场调研、新闻聚合等领域。借助其自动化抓取能力,企业和研究机构能够实时把握市场动态,追踪竞争对手信息,提升决策的科学性和时效性。
此外,Web Fetch工具还可以与机器学习、大数据分析等技术结合,对抓取的数据进行深度挖掘,进一步释放数据的商业价值和社会价值。为了提升抓取效率和减少被反扒机制识别,现代Web Fetch工具还采用了分布式抓取、多线程请求以及动态渲染处理技术。通过模拟真实用户行为,随机切换IP地址和请求头,工具能够降低被封禁的风险,保障长期稳定运行。与此同时,对于基于JavaScript渲染的网页,工具集成了无头浏览器或浏览器自动化框架,实现对动态内容的全面获取。随着人工智能和自然语言处理技术的发展,Web Fetch工具的智能化水平不断提升。具备语义理解、多语言处理和结构化数据生成能力的新型工具,使得复杂网页的数据提取变得更加简单和精准。
开发者可以借助这些智能能力,快速构建符合特定业务需求的数据抓取方案,减少手工干预和后续清洗的工作量。安全性也是Web Fetch工具设计中的重要考量。合理尊重网站的robots.txt规则,避免过于频繁的请求造成服务器压力,遵循法律法规和道德规范,确保数据抓取行为合法合规,既保护自身权益,也维护网络生态的和谐发展。从技术实现角度来看,Web Fetch工具支持多种编程语言和框架,如Python、JavaScript、Java等,其中Python因其丰富的网络请求库、爬虫框架(如Requests、Scrapy、BeautifulSoup)而备受青睐。现代工具还提供了图形化界面和API接口,方便不同层次的用户快速部署和集成,适应多样化的使用需求。总的来说,Web Fetch工具作为网络数据采集的重要技术手段,正随着互联网环境和用户需求的演进不断进化。
它不仅帮助用户高效抓取和管理海量信息,还推动了人工智能、大数据等技术的深度融合应用。未来,随着算法优化和智能技术的发展,Web Fetch工具有望在数据精准度、动态适应性和解决复杂网页抓取难题方面实现更加突破性的提升。掌握并善用Web Fetch工具,将为企业和开发者创造巨大的竞争优势和创新机遇,在数字经济时代占据先机。 。