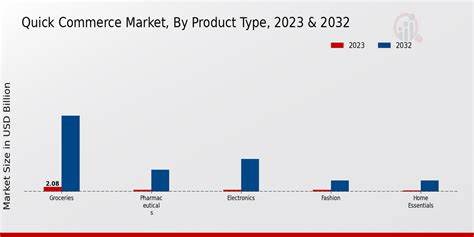
随着数字化时代的不断推进,快商(Quick Commerce)作为零售领域的新兴力量,以其速度快、服务精细、覆盖广的特点迅速崛起。消费者对即时配送的需求推动了快商模式的发展,品牌在这一领域的成功往往依赖于对海量数据的精准掌控。数据不仅决定了运营的效率,更成为品牌洞察消费者行为、优化产品组合、提升销售业绩的重要源泉。因此,建立一套实时高效的数据分析体系,成为品牌在快商竞争中制胜的关键。 快商的核心优势是极致的时间敏感性,任何延迟都可能导致销售机会的流失和客户满意度下降。在这种背景下,传统依赖每日批量更新的分析方法显然无法满足需求。
品牌需要一种实时反馈机制,能够随时了解产品销售趋势、库存状态、用户搜索与转化数据以及不同细分品类的表现,从而即时调整推广策略和补货计划,快速响应市场变化。 过去,许多初创企业选择使用成熟且熟悉关系型数据库如PostgreSQL,快速搭建品牌数据分析的最小可行产品(MVP)。这种方式可以帮助企业在初期以较低成本快速投产,收集用户反馈。然而,随着业务扩展,数据规模和复杂度的激增给传统数据库性能带来了极大压力。数亿级别的交易数据与多表复杂联结查询在Postgres上运行变得低效,响应时延拉长,用户体验降低,恰恰不适合要求极高的快商场景。 面对急剧增长的品牌合作伙伴和丰富多样的产品目录,企业必须寻找一种面向在线分析处理(OLAP)的解决方案,能够承载海量数据并实现秒级响应。
经过多方评测,如ClickHouse和Apache Pinot等流行的OLAP数据库各有优势,但在支持复杂联结查询、高并发用户访问及与现有数据管道无缝集成方面存在不足。而StarRocks以其卓越的查询性能和灵活的数据摄取方式脱颖而出,成为理想选择。 StarRocks的关键优势在于其优化的联结处理能力,能够在处理超过三亿行数据时保证P99响应时间低于500毫秒,为品牌提供极其流畅的实时分析体验。其支持通过Kafka和S3(Parquet格式)直接摄取流式和批量数据,与企业既有的Databricks数据湖架构良好互动,极大简化了数据管道部署和维护工作。 在架构设计上,企业选择了StarRocks的“shared-nothing”模式,即独占本地存储以换取更低的查询延迟和更高的性能表现。对于快商这样对实时性要求极高且数据体量尚未达到PB级的场景而言,这种架构兼顾了系统的稳定性与扩展性,保障了品牌数据平台的高效运行。
数据摄取策略从最早的每日批量同步逐步进化为结合Pipe Load与Routine Load两大流程。Pipe Load通过持续扫描存储于S3的Parquet文件,实现数据的自动更新,满足了批量数据的及时导入需求。Routine Load通过Kafka流直接摄取处理后的实时事件数据,确保销售、浏览、库存等关键指标能够在几秒内反映到分析平台。如此一来,品牌不仅获得了历史销售数据的全貌,也能实时洞察当日的流量与转化动态,实现前所未有的决策时效性。 在数据处理链条中,Apache Flink承担实时流处理职责,对海量事件进行清洗、筛选与五分钟级别的聚合,优化数据存储结构并提升查询效率。紧接着该处理结果进入StarRocks,通过其强大的分析引擎为品牌用户提供具有高度交互性的分析工具。
用户可在界面上自由组合筛选条件,快速洞察不同城市、产品类别、时间窗口的销售绩效及用户行为,帮助品牌方把握市场趋势,灵活调整营销和库存策略。 这套由Postgres起步到StarRocks成熟运营的品牌分析平台,不仅提升了查询性能,还极大地增强了系统的稳定性与可维护性。每秒六万条事件的高吞吐、高可靠数据流,保证了系统能够承载业务高峰期的并发访问,满足品牌用户对实时数据的迫切需求。 凭借这套数据驱动的品牌分析体系,品牌能够比以往更快识别爆款产品与滞销品,更准确调整库存水平,避免断货或积压风险。同时,用户搜索关键词和转化路径的实时跟踪,助力营销团队优化广告投放与推荐算法,精准触达目标消费者,提升转化率与客户满意度。 未来,基于StarRocks不断优化的性能和企业不断完善的数据生态,快商品牌分析工具将进一步引入机器学习与预测分析功能,在实时数据的基础上为品牌提供智能预测和风险预警,全面提升业务敏捷性和市场竞争力。
此外,随着数据规模的扩大与复杂度增加,企业还计划探索优秀数据库的横向扩展能力和弹性数据存储架构,以支持更大体量的业务增长。 结语,随着快商行业进入高速发展期,企业如何通过技术手段提升品牌数据能力,已成为差异化竞争的重要策略。构建实时、高效、用户友好的品牌分析平台,不仅帮助品牌把握每一次商机,还推动整个快商生态向更加智能和数字化的方向发展。未来,数据驱动决策将成为品牌制胜的核心力量,推动快商模式开拓更广阔的市场天地。