近年来,随着大型语言模型(LLMs)的迅猛发展,Transformer架构成为自然语言处理领域的核心技术。然而,尽管这些基础模型功力深厚,其泛用性极强,但在面对不同具体任务时,通常需要进行专门的适配和微调。这种适配过程不仅耗费大量计算资源,还需要专业的调参和数据准备,限制了其在实际应用中的灵活性和普及速度。针对这一瓶颈,美籍泰国学者Rujikorn Charakorn及其团队提出了名为Text-to-LoRA(T2L)的创新方法,开启了Transformer模型适配的新篇章。Text-to-LoRA通过自然语言描述,实现对基础模型的即时微调,极大地简化了适配流程,降低了计算成本,为AI的多样化应用开辟了更便捷的道路。 传统的微调方法通常需要收集大量高质量的带标签数据,反复训练模型以获得针对任务的定制能力。
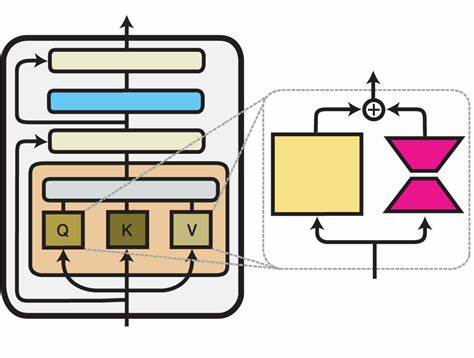
这种方法不仅对资源消耗极大,还因超参数调节复杂,容易导致模型在训练过程中性能波动。此外,多任务情况下需要为每个任务训练单独的适配器,存储和维护成本各显著提升。相比之下,LoRA(Low-Rank Adaptation)技术通过增加低秩矩阵适配层,实现了参数高效调整,大幅度降低了微调的存储和计算开销。Text-to-LoRA则是在LoRA基础上升级,通过一个超级网络(hypernetwork)机制,直接通过文本描述生成LoRA适配器,无需重新训练主体模型,且仅用一次前向传播即可完成任务适配。 Text-to-LoRA的工作原理主要包括两个关键步骤:首先,设计并训练一个超网络,该网络学习如何根据任务的自然语言描述生成对应的LoRA参数;其次,当用户提供新的任务描述时,超网络能够快速地构造出适用于基础模型的定制LoRA,完成针对指定任务的微调。这一过程完全摆脱了昂贵的模型微调步骤,且不再依赖于大量任务特定数据,实现了真正意义上的“零样本”任务适配。
在实验方面,Text-to-LoRA选取了9个公开预训练的LoRA实例作为训练集,涵盖包括数学题解(GSM8K)、编程任务(Arc)等多样化类别。训练完成后,模型生成的LoRA适配器在相应测试集上表现出色,与传统任务特定微调适配器的性能相当甚至优于部分实例。值得一提的是,超网络不仅能够压缩数百个预训练LoRA实例的信息,还能在完全未见过的任务上实现零样本泛化,体现出极强的通用性和灵活性。 这种技术突破的意义远超性能指标。首先,从应用角度看,它大幅降低了大规模模型应用的入门门槛,普通用户只需简单描述任务需求即可调整模型,极大拓宽了基础模型的使用场景。其次,训练和推理计算成本显著减少,为边缘计算设备和资源受限的环境提供了可行的解决方案,有助于将先进AI技术下沉到更多行业和地区。
最后,Text-to-LoRA也为未来研究方向提供了新的思路,期待更多围绕自然语言引导的模型微调技术出现,推动AI系统向更智能、便捷和人性化发展。 Text-to-LoRA还体现了当前人工智能领域向“民主化”、“易用化”转变的趋势。传统深度学习模型,尤其是在微调阶段往往要求高专业门槛,而通过自然语言描述实现模型适配,则极大缩短了技术传播链条,让更多非专业人士能够快速获得定制化AI能力。该项目由Simons基金会等机构支持,研发团队开放了源代码,学界与业界能够基于此进一步提升与创新。 尽管Text-to-LoRA表现亮眼,仍有部分挑战亟待克服。例如,基于文本描述的适配效果依赖于描述的准确性和完整性,不同语言表达可能导致适配性能的波动;此外,超网络本身的训练需要覆盖丰富多样的任务分布,才能保障在未知任务上的泛化能力,因此数据样本和训练策略仍需不断优化。
未来融合更多的多模态信息、提升对复杂任务的支持、有助于Text-to-LoRA迈向更广泛实践。 总的来说,Text-to-LoRA开创了利用自然语言即时适配Transformer模型的先河,突破了传统微调框架的限制,实现了低耗高效的模型定制。它不仅提升了大模型的实用价值,也为智能服务领域带来了更多可能性。随着研究的深入和应用的扩展,基于文本驱动的即时适配技术将有望成为人工智能生态系统的重要支柱,助力构建更加开放、灵活且人性化的智能世界。