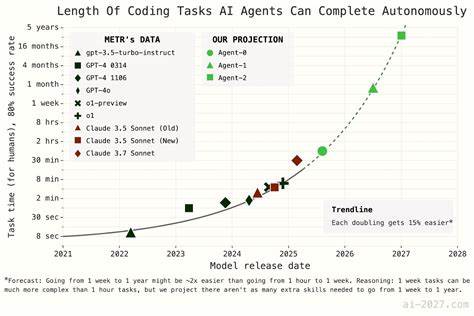
近年来,随着人工智能技术的突飞猛进,关于人工智能何时达到超级智能、甚至实现技术奇点的预测话题愈发受到关注。其中,名为AI 2027的报告因其详细的时间线预测模型和引人入胜的短篇故事描述而迅速走红,成为不少公众和学界讨论的焦点。然而,对其模型的深入分析显示,该报告的时间预测存在诸多逻辑漏洞、参数设定上的疑问以及缺乏实证依据的问题,值得我们深入反思和警惕。AI 2027模型的核心目标是预测何时出现“超人类编码者”,即能以远超人类的速度和成本效益完成AI研发任务的智能体。模型采用了两种主要方法:时间跨度延展法与基准与差距法,其中时间跨度延展法试图根据当前AI完成特定任务的时间跨度的增长趋势进行外推,基准与差距法则试图通过预测AI在标准化基准测评上的表现,推导未来进展路径。尽管表面上看,模型聚合了大量数据和专业人士的评估,但其根本结构与参数选择却存在诸多问题。
首先,从时间跨度延展法来看,模型对于所谓的“超指数增长曲线”的运用令人质疑。所谓超指数增长意味着AI能力提升速度本身也呈加速状态,具体表现为每次能力翻倍所花费的时间缩短10%。此设定在数学上蕴含一个极限点,模型预测会出现“时间跨度”值趋近无穷甚至奇异的点,结果导致该曲线在2030年前后出现数学异常。这种设定不仅缺乏充分的理论支撑,也未对其可能带来的非物理性结果给予合理解释。从概念层面而言,模型对超指数增长的支持理由亦不充分。报告提及例如内部与公开发布差距缩小、任务复杂度变化及最近AI进展加速等因素,试图佐证这一增长趋势。
实际上,这些论据存在逻辑漏洞,甚至部分反而指向增长放缓的可能,如内部发布提前会导致外部数据呈现虚高进展,任务难度对AI而言可能随时间非单调变化等。此外,模型在速度加速中的“中间速度提升”机制也存在自相矛盾之处。虽然尝试将AI辅助研发带来的加速纳入考量,但其算法设计导致模型回推历史时不符合用户预期的现实估计,从而降低预测可信度。参数分布的选择及缺乏对关键参数不确定性的充分表达,更增加了模型输出结果的脆弱性。对基准与差距法的分析则暴露出另一系列问题。该方法通过拟合Re-bench基准测试数据,预测AI什么时候会达到或超过最佳人类表现。
然而,模型对Re-bench的饱和点设定基本是一种主观假设,而非基于可靠数据拟合,且实际代码对该步骤的计算基本忽视,导致该部分“核心预测”实际上对最终模拟无显著贡献。该方法仅凭主观参数对未来进行断言,结果难免使人怀疑其学术严谨性。模型对时间跨度参数及开发速度参数的猜测缺乏坚实依据,实际应用时难以兼顾不同层次的AI进步因素,这使得模型难以捕捉AI研发中的复杂动态。值得注意的是,AI 2027的作者在后续更新中虽对模型增加了一些复杂度,如引入不确定性参数、细分中间速度加速机制和延迟超指数增长开始时间等调整,但这些改进未从根本上解决核心问题。更复杂的模型结构反而增加了解释难度,且缺乏充分的验证过程,使得预测结果的可靠性仍然存疑。对历史数据的拟合也未见明显提升,这意味模型依旧难以准确描绘过去,也难以稳健预测未来。
整体来看,AI 2027的时间线预测虽具备疫情数据采集和量化模型的特色,但其预测结果并非严格的科学结论,而更像是基于若干假设前提的探索性推演。模型本身忽视了AI发展中大量外部变量,如政策环境、资金投入、人才分布以及技术瓶颈等不可控因素,从而导致模型所展现的置信区间远远低估了真实不确定性。此外,对模型核心指标的定义——“超人类编码者”的具体能力边界,缺乏清晰且实用的标准,也进一步削弱了预测的现实意义。对于公众和决策者而言,跟随这类预测进行大规模规划或改变策略,极易陷入过度自信或认知偏差而产生严重后果。由此,我们应当鼓励更为多元、开放且系统的预测方法,引入更多实证研究,加强对AI开发流程和成果评估的透明化与追踪,才能逐步提升对AI自主研发速度的理解水平。与此同时,有效面对诸多不确定性,构建稳健灵活的政策和战略,或许比过度倚赖单一预测模型更为明智。
总的来说,AI 2027在人工智能发展时间轴预测中暴露出模型设计的常见问题与潜在风险。严格的模型验证和谨慎的假设制定不可或缺,尤其在面对极度复杂且快速变化的技术领域时更显重要。作为社会各界关注的热门话题,AI未来发展前景的科学预判仍任重道远,需要跨学科合作和多样化视角的持续探索。只有避免陷入对单一模型的盲目信赖,积极吸纳批判性意见和广泛数据,才能收到更切实有效的预测效果,为应对人工智能带来的深远影响奠定坚实基础。