在数字化时代,网站内容成为企业和机构的重要资产。然而,随着人工智能技术的飞速发展,尤其是大型语言模型(LLM)的普及,网站数据遭受自动抓取机器人的侵袭现象愈加严重。这些AI驱动的抓取机器人不断访问网站,批量收集文本、图片甚至结构化数据,给内容版权、服务器性能乃至用户体验带来了极大威胁。为应对这一挑战,反AI/LLM抓取机器人防火墙应运而生,成为维护网络安全和数据隐私的关键工具。反AI/LLM抓取机器人防火墙通过多层检测技术,有效识别和拦截非人类访问行为,确保网站只对合法用户开放。该防火墙通常具备多种先进机制,既能吓退恶意机器人,也能诱导其暴露身份。
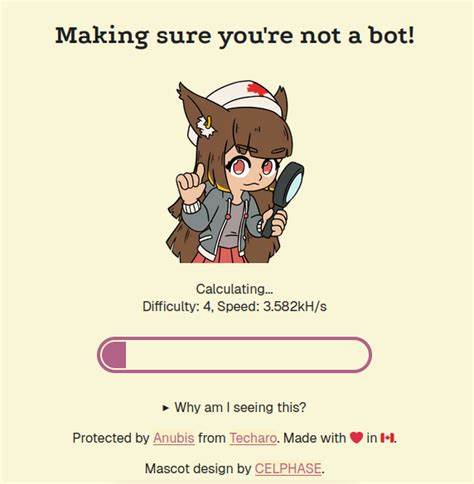
首先,防火墙会对每个HTTP请求进行实时校验,主要基于访问者的行为特征和技术细节,判断其是否为真实用户。通过引入类似人机交互的验证流程,如图形验证码、行为空间分析等,提升机器人通过验证的难度。其次,Proof-of-Work(工作量证明)机制成为该防火墙的重要组成部分。通过要求访问者解决一定难度的计算任务,显著提高自动化抓取机器人的资源消耗,降低其批量抓取效率。真实用户几乎察觉不到这一过程,但机器人却需消耗大量计算资源才能通过验证。第三,防火墙利用HMAC(散列消息认证码)和JWT(JSON Web Token)技术保障访问令牌的安全性和唯一性。
通过此手段,只有携带有效且未被篡改令牌的请求才能访问后端服务,防止伪造和重放攻击。第四,陷阱端点设计被应用于防火墙策略中。通过在网站中设置专门的"陷阱"链接或接口,一旦被抓取机器人访问,系统即可捕捉其行为并主动封禁或引导其进入陷阱区域,从而保护真实内容不被泄露。最后,防火墙还会向被确认的机器人返回错误或迷惑性的内容,以"毒化"自动抓取的语料库,降低其数据的准确性。这种策略不仅能够保护原始内容的版权,还能使抓取机器人的训练结果失真,严重削弱其有效性。实用层面上,反AI/LLM抓取机器人防火墙具有高度的可定制性。
网站管理者可以根据自身需求,调整挑战难度、配置验证策略以及设定陷阱的触发条件。全方位的配置支持让该防火墙适用于新闻门户、电商平台、学术资源库等多种网络环境,满足不同规模和业务场景的防护要求。技术实现上,诸如Fantasma Cero这一基于Rust语言开发的开源项目,提供了强大且灵活的框架,帮助开发者快速集成和部署防火墙。Rust语言的高性能和内存安全特性,确保系统运行稳定且抵御复杂攻击。部署防火墙后,网站服务器的负载不仅得到有效控制,还显著减少了因恶意抓取带来的带宽浪费和潜在风险。同时,用户体验得以提升,真实访问者的浏览速度和响应时间明显改善。
值得注意的是,反AI/LLM抓取机器人防火墙并非万能保险箱。随着技术的不断演进,抓取机器人也在不断进化,利用高级混淆技术和模拟人类行为手段试图绕过防护。因此,持续更新防火墙算法、结合人工智能检测以及加强综合安全策略,成为抵御未来威胁的必然方向。业内专家普遍认为,防火墙作为内容安全防护体系的重要一环,应与内容版权管理、法律法规合规检控紧密配合,实现多层次、多维度的防御策略。唯有如此,才能在AI浪潮下守护数字内容的价值和生态健康。未来,随着人工智能普及程度的加深,互联网安全形势愈加复杂,反AI/LLM抓取机器人防火墙的作用将愈发凸显。
结合大数据分析和行为建模技术,防火墙的智能化水平将进一步提升,更精准地区分恶意机器人与真实用户,助力网络空间秩序重建和良性发展。综上所述,反AI/LLM抓取机器人防火墙作为新时代网站安全守护者,为内容保护和流量管理提供了有力利器。面对日益猖獗的自动化抓取行为,网站运营者应积极采用该类技术,构筑坚实的防护壁垒,确保数字资产安全与业务持续稳定发展。 。