近年来,人工智能模型在各个领域的应用愈发广泛,而如何在浏览器端实现高效的AI推理成为技术探索的重要方向。Llama-3.2作为强大的语言模型,因其卓越的性能和灵活性受到了广泛关注。通过WebGPU技术结合本地模型加载,开发者和AI爱好者可以在无需网络环境下,直接在浏览器中运行Llama-3.2模型,体验前所未有的高性能推理效果。Llama-3.2的WebGPU版本,是基于transformers.js库构建的,旨在利用现代GPU的并行计算能力加速模型推理流程。传统方式往往依赖通过网络下载大型模型文件,耗时且对网络质量有较高要求,尤其是在模型文件体积通常超过1GB的情况下。为了绕开这一限制,实现从本地文件夹直接加载模型文件,是提升用户体验和响应速度的关键。
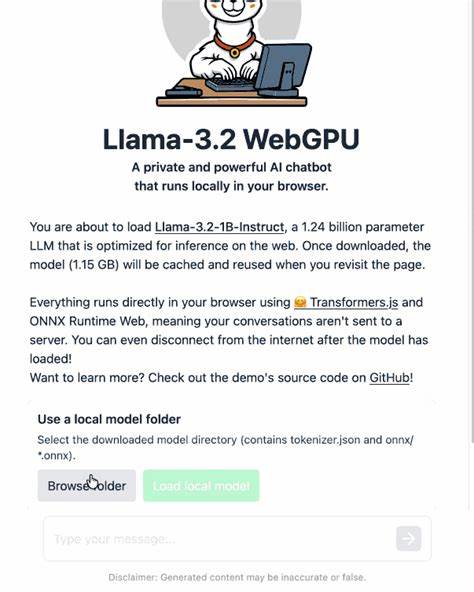
浏览器的新兴API WebGPU为此提供了极佳的支持。WebGPU作为继WebGL之后更强大和灵活的图形计算接口,专注于现代GPU的计算能力,使得浏览器端机器学习任务具备更快的执行效率和更低的延迟。用户只需在支持WebGPU的浏览器环境中,比如Chrome或Firefox Nightly,便能享受强大的GPU加速效果。在加载本地Llama-3.2模型时,资源占用和文件读取的安全性成为重点考察因素。通过设计简洁的用户界面,提供浏览文件夹的按钮,用户即可选择本地存储的模型文件夹,浏览器会在获得用户确认后读取文件内容,而无需将数据上传至服务器,增强隐私保护和数据安全。实现这一功能的核心在于修改transformers.js中的原有逻辑,将模型加载路径从远程网络切换为用户选择的本地路径。
利用JavaScript的File System Access API,代码能够访问用户同意的本地文件或文件夹,配合WebGPU完成模型初始化和执行。该改进不仅减少了等待模型下载的时间,也避免了因网络不稳定带来的加载失败,同时使得AI模型使用更加灵活,用户可以携带多种本地模型版本以满足不同的应用需求。在实际操作中,用户首先需要从开源社区或模型托管平台上获取Llama-3.2的ONNX格式文件,通常通过Git LFS等工具克隆相应仓库即可获得。由于模型文件较大,约1.2GB,建议提前准备充足的存储空间和稳定的硬盘性能。随后,用户进入修改后的WebGPU Llama-3.2演示页面,点击"浏览文件夹"按钮,选择已下载的模型所在文件夹,执行本地文件读取确认。加载成功后,用户即可在浏览器中启动交互式聊天或推理体验,无缝享受本地模型带来的高速响应。
这种离线加载模式同样为开发者拓展模型支持提供了便捷途径。未来只需稍作修改和适配,transformers.js框架便可兼容更多其他语言模型格式,构建多样化的本地AI生态。此外,本地加载功能也促进了AI应用在隐私敏感场景下的应用,比如医疗、金融、个人助手等领域,数据不出设备,降低了泄露风险。值得注意的是,目前WebGPU仍处于不断演进中,尽管已经在主流浏览器中实现,但用户需确保浏览器版本和硬件GPU支持最新的接口规范,以保证兼容性和性能。随着浏览器和硬件的逐步迭代,基于WebGPU的AI推理体验将更为流畅和普及。总的来看,从本地文件夹加载Llama-3.2 WebGPU模型,既满足了高性能推理的技术需求,又响应了用户对隐私和使用便捷性的期望。
该方案代表了浏览器端人工智能发展的一大趋势,即充分发挥浏览器和客户端设备的算力优势,减少对云端依赖,实现功能灵活、响应快速且安全可靠的智能应用。对开发者而言,掌握相关技术栈和思维,探索本地模型加载的深度优化,无疑是未来构建创新型AI产品的重要切入点。随着AI开源社区的不断壮大和技术的快速更新,期待更多基于WebGPU的高效AI推理应用涌现,为用户带来更丰富、多样且安全的智能体验。 。