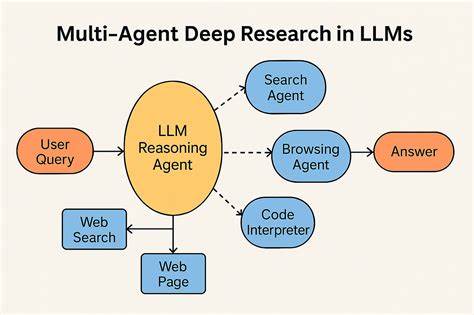
随着人工智能和自然语言处理技术的迅猛发展,利用大型语言模型(LLM)实现智能化信息检索和知识整合已成为热点。DeepResearch代理作为一款基于LangGraph理念开发的开源NPM包,完美结合了LLM模型、多样搜索引擎以及基于检索增强生成(RAG)的访问机制,极大创新了传统的信息搜索和智能问答方式。它不仅能高效完成复杂的网络调研,而且通过动态查询生成与反思机制,持续优化检索效果,满足用户对精准和权威信息的需求。DeepResearch的设计思想受Google Gemini LangGraph项目启发,在智能代理研究领域展现出强大的应用潜力。该项目基于Node.js环境构建,用户可轻松通过npm或yarn引入该包进行开发集成,支持任何符合OpenAI接口规范的LLM模型以及自定义的搜索器函数以接入主流搜索引擎,如Google、Bing等。DeepResearch的核心流程涵盖了多个阶段。
首先,系统根据用户输入,利用强大的语言模型自动生成多个切题的搜索查询语句。这一过程的动态生成不仅基于简单关键词,更借助上下文和语言理解能力,实现查询表述的多角度覆盖。接着,针对每一个生成的查询,DeepResearch调用预设搜索器函数执行搜索动作,获取相关网页或知识库的信息。然后,系统进入反思阶段,利用另一模型对检索结果进行深度分析,识别内容的知识盲区和信息不足之处。这种以反思为核心的调控机制保证了研究的深度和广度,避免了单次搜索可能带来的信息偏差和遗漏。如果发现信息存在缺口,DeepResearch可以继续生成后续的补充查询,进行多轮迭代检索,不断完善知识结构。
最终,系统将所采集和分析的知识信息经过语言模型加工整合,输出一份具备丰富引用和出处说明的权威答案,极大提升了结果的可信度和实用价值。除了完整的研究闭环,DeepResearch还支持流式传输功能,开发者可以通过stream或streamEvents方法实时获取生成的文本内容及搜索节点的最新动态。这一点对于需要即时反馈和交互的场景尤为重要,有利于实时监控模型生成过程以及动态调整策略。实现流式效果的能力,使得DeepResearch不仅适合传统批量任务,也能支持多样化的交互式智能应用。在技术实现上,DeepResearch代码库主要由TypeScript编写,结构清晰,维护简便。核心组件包括查询生成节点、研究节点、反思节点和答案整合节点,整体架构符合现代智能代理设计理念。
项目以Apache 2.0开源许可证发布,便于开发者自由使用和二次开发。DeepResearch相较于传统单次搜索引擎查询的最大优势在于其多层次、多轮次、多模型的协同工作能力。它不单纯依赖关键词匹配,而是融入了深度语义理解和推理能力,能够不断完善查询策略和结果质量,从而实现更准确、更全面的知识探索。这对于学术研究、企业智能问答、内容创作以及各种需要精准信息汇总的场景都非常有价值。对于开发者而言,DeepResearch的使用门槛较低,配合符合RESTful标准的LLM接口及自定义搜索函数即可快速搭建属于自己的智能研究代理。官方示例代码展示了从实例化对象、调用compile方法到调用stream事件监听的全流程,极大便利了产品原型开发和功能定制。
同时,支持不同的语言模型与搜索引擎组合,具有良好的扩展性和灵活性。未来,随着大模型能力的提升和知识图谱技术的融合,DeepResearch所代表的智能研究代理有望进一步升级,支持更复杂的推理链路和多模态信息处理,成为知识管理领域的重要工具。它的开放架构和社区生态也为更多创新玩法留足空间。总结来看,DeepResearch作为一款开源智能研究代理项目,基于LangGraph理念,以强大的LLM模型和灵活的搜索策略相结合,实现了动态、多轮、带反思的自动研究流程。无论是科研人员、数据分析师,还是内容创作者,都能通过该工具显著提高信息获取速度和答案质量。其流式传输能力和扩展接口,使得这一项目不仅具备即用性,更具备广阔的开发潜力和应用前景。
未来期望更多领域能够借助DeepResearch,实现智能化的知识发现与问题解决,为人工智能赋能信息时代提供坚实助力。