随着人工智能和大数据技术的迅猛发展,高维向量数据的处理和计算需求也日渐增长。Faiss,全称Facebook AI Similarity Search,是Facebook人工智能研究团队于2017年推出的一款高效相似性搜索库。它专注于处理大规模、多维度的向量数据,解决传统数据库和搜索引擎面对高维相似性搜索时的性能瓶颈问题,为图像检索、自然语言处理、推荐系统等领域提供了强有力的技术支持。 传统数据库在处理结构化数据时表现优异,但面对由深度学习等AI技术生成的高维向量数据时显得捉襟见肘。如今,从图片、视频到文本,越来越多的信息以向量形式表达,这些表达依赖于神经网络生成的嵌入向量,能够更精准地刻画数据之间的语义相似性。然而,传统的关系型数据库不适宜进行这些向量的快速距离计算,相似性搜索在亿级甚至十亿级别的向量集合面前更是变得极为困难。
Faiss针对这一挑战,以高效算法设计和硬件加速为核心,率先实现了在亿级规模数据集上进行近邻搜索的突破。其核心功能包括基于欧氏距离和内积的相似度计算,通过先进的索引构造技术,将大规模数据压缩编码,大幅降低内存占用的同时保证搜索精度。 在实现技术上,Faiss融合了多线程处理和SIMD指令优化,提高CPU计算效率。同时,Faiss拥有业界领先的GPU实现,其k最小(k-selection)算法被誉为目前GPU环境下速度最快的方案之一。这项优化允许Faiss在单机多GPU配置上轻松应对上亿向量的并行检索,显著提升实时查询吞吐量。 Faiss结构灵活,提供多种索引类型,从简单的暴力搜索(IndexFlatL2)到复杂的产品量化(Product Quantization)和倒排多索引技术。
索引设计允许用户根据内存限制、计算资源和准确率需求,灵活选择合适策略。在亿级别规模测试中,Faiss能够在30GB内存范围内,利用预处理、分区和压缩编码,实现超过400%的性能提升,同时保证检索结果的准确性满足业务场景。 应用层面,Faiss广泛用于图像相似性检索,帮助用户从海量图片库中快速找到近似图像。比如,用户上传一张建筑照片,Faiss通过向量搜索发现数据库中所有类似外观的建筑图像,无需记忆具体名称信息。此外,在文本语义搜索、推荐引擎中,Faiss也被用来匹配相似用户、相似内容,大幅提升搜索效率和推荐精准度。 Faiss的成功另一个关键在于其开源特性和易用接口。
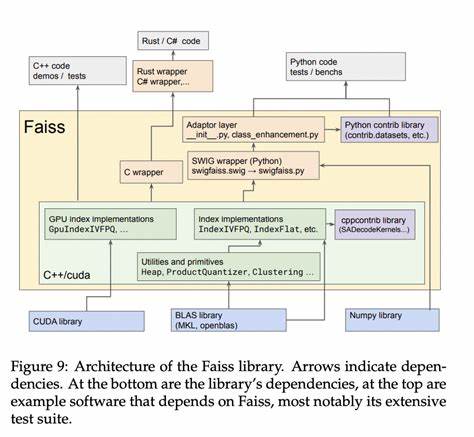
它以C++实现,并提供Python绑定,轻松集成至现有AI与数据处理流程。开发者通过简单API就能构建高效索引、添加向量及执行搜索,同时支持GPU透明切换,毫无门槛地借助硬件加速能力。因而Faiss迅速被学术界和业界广泛采用,成为基础的相似性搜索库之一。 从工程架构看,Faiss开发团队注重底层性能的极致挖掘。采用BLAS矩阵乘法库优化了距离计算,利用内存带宽和计算能力的roofline模型指导设计,最大化硬件利用效率。GPU端算法设计充分利用寄存器与浮点计算特性,执行单遍高效k选择,兼顾精确和近似的平衡。
多GPU数据分片机制使得可扩展性和并行性能达到新高度。 面对未来,Faiss正在持续扩展适配的新硬件平台和索引算法,支持更大规模数据和更高维度向量。人工智能应用日益复杂,向量维度增长和数据持续积累对搜索性能提出更高要求,Faiss的技术路线与工程经验为应对这一趋势提供坚实基础。此外,生态建设和社区活跃度也在快速增长,推动用户贡献更多扩展和优化方案。 综上所述,Faiss作为一款高效、灵活且成熟的相似性搜索库,以其开创性架构和创新算法,解决了高维大规模数据快速检索的核心难题。它的出现不仅提升了多媒体内容检索的用户体验,也极大地推动了人工智能领域中向量搜索技术的发展。
未来,随着搜索需求和计算硬件的不断进步,Faiss势必在智能检索和数据分析领域继续发挥引领作用,引导相似性搜索技术向更广阔的应用场景延展。