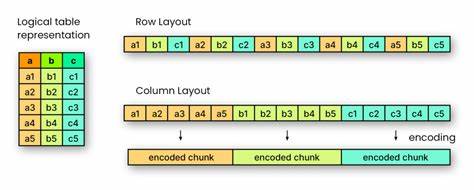
Apache Parquet作为现代大数据领域广泛应用的列式存储格式,其高效的存储能力和查询性能备受行业关注。自2013年由Cloudera和Twitter共同开发并捐赠给Apache软件基金会以来,Parquet迅速成为构建数据仓库、数据湖以及机器学习管道的关键技术组件。其优异的性能很大程度上依赖于数据存储过程中应用的多种压缩与编码机制,其中字典编码和Snappy压缩是核心技术手段。理解这两种技术在Parquet中的协同作用,有助于更好地把握数据存储效率和查询响应速度的提升路径。字典编码以其语义层面的数据重复优化著称。它通过构建数据列中重复值的映射字典,将频繁出现的字符串或其他数据类型替换成简洁的数字键。
举例来说,若某列包含大量重复的文本值如产品名称或地理区域,字典编码通过将这些文本替换成对应的数字索引,大幅减少存储空间需求,同时优化数据读取时的内存访问效率。字典编码不仅降低了数据的冗余性,也为后续的压缩阶段提供了更有利的输入数据信号。紧接着,Parquet采用的Snappy压缩是一种轻量级且高效的字节序列压缩算法。不同于字典编码的语义理解,Snappy工作在数据的字节层面,通过识别并替换重复出现的字节模式和字节块,实现快速且合理的压缩比。Snappy的设计目标侧重于压缩速度,确保在大量数据处理过程中能够维持高吞吐量,避免成为性能瓶颈。结合字典编码先将数据结构简化后,再由Snappy进行字节级压缩,Parquet能同时保证数据文件体积小和数据处理速度快。
在实际应用场景中,比如流媒体分析,大量的观众行为数据会包含重复的节目名称、时间戳和用户标识符。利用字典编码,Parquet能够将高频重复值用数字索引取代,极大地减少数据的结构复杂性。接着,Snappy压缩对字典编码结果进行字节级处理,进一步压缩数据大小。两者结合,使得即便是数十亿条记录的数据集,也能被高效存储和快速查询。值得注意的是,字典编码和Snappy压缩的组合并非自然而然的叠加,而是经过精心设计的分层优化。字典编码从数据的语义角度入手,最大限度减少重复信息,Snappy则从字节级别保障数据的紧凑性与快速处理能力。
Parquet将两者有效结合,确保了在大规模数据分析场景中的响应速度和资源消耗的平衡。此外,Parquet文件结构中,将每一列的数据划分为多个“页面”,每个页面应用单独的Snappy压缩,使得数据加载可以实现更加精细的控制。例如,在查询只涉及部分列或范围时,能够仅解压相关部分的页面,进一步提升查询效率。作为开源生态系统的重要组成部分,Parquet的这种高效数据编码和压缩策略,也促进了生态中众多计算引擎如Apache Spark、Presto、Hive等的优化配合。它们均能利用Parquet的数据格式特性,减少I/O和计算压力,提高任务运行速度。同时,Parquet的设计理念还强调可扩展性和兼容性,允许根据特定应用场景调整编码和压缩策略,如支持不同的压缩算法选项以及编码方式选择,满足多样化需求。
随着云计算和大数据技术的不断发展,数据规模呈指数级增长,如何在保证数据完整性和可用性的前提下,实现存储和计算资源的高效利用,成为关键挑战。Parquet凭借字典编码与Snappy压缩相辅相成的技术架构,为企业和开发者提供了一种成熟且高效的解决方案。未来,结合机器学习和智能化数据管理技术,Parquet及其压缩编码技术有望继续演进,进一步提升存储压缩率和查询性能,助力大数据应用迈向更智能、更高效的阶段。理解Apache Parquet的字典编码和Snappy压缩,不仅有助于技术人员优化数据架构,也为业务决策提供更坚实的数据基础支持。