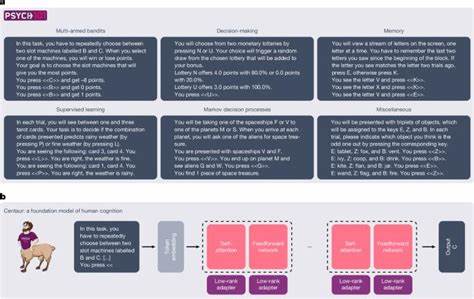
随着人工智能技术的飞速发展,特别是在自然语言处理和信息检索领域,检索模型正在从传统的关键词匹配向更加智能的指令驱动演进。信息检索不仅仅局限于简单的文本匹配,而是依托大规模预训练和指令训练使得模型能够理解复杂的任务需求,并提供更精准的搜索结果。近期由Sun等人发布的MAIR(Massive Instructed Retrieval Benchmark)基准,正是顺应这一趋势应运而生,旨在为指令驱动型检索模型的评测提供更具挑战性和多样性的测试平台。MAIR冻结了一个庞大而异质的测试环境,集成了126个不同的检索任务,横跨自然语言处理、社交媒体、法律文档、电子商务、学术搜索等6大领域,全面覆盖了当前信息检索应用场景。传统的检索基准往往聚焦于单一任务或有限类型的查询,难以反映最新指令调优模型在实际复杂环境中的表现。而MAIR以其“多任务、多领域、多指令”的特征,有效突破了评测的局限,为研究者提供了检验模型泛化能力和适应多样需求的关键工具。
MAIR的构建基础是从现有广泛认可的数据集中精选并整合出的任务样本,这些任务涵盖了文本匹配、上下文理解、问题回答、相关性排序等多种信息检索核心技术。通过统一的接口和评价指标体系,MAIR能够系统地对比不同模型在各类检索情境下的性能差异。从实验结果来看,指令调优过的文本嵌入模型及重排序模型整体展现出优于非指令调优模型的性能,说明明确的任务指令可以极大提升模型对多样需求的理解力和执行力。然而,研究者们也发现,这些模型在长尾任务(即数据稀缺或查询复杂度高的情况)上的表现仍显不足,存在较大的提升空间。这提示未来的研究方向应进一步优化模型的跨任务适应能力,强化模型在稀缺资源环境中的稳定表现。MAIR的公开发布不仅为学术界提供了一个公平、权威的评测平台,也推动业界加速发展智能检索技术,助力搜索引擎、智能问答系统及推荐系统的性能提升。
结合大规模指令数据训练的检索模型,正逐渐成为信息获取的主流趋势,其有效评测机制则是确保技术进步的基石。从长期角度看,MAIR通过覆盖多种语言风格、任务复杂度和应用场景,为构建更加智能、人性化的检索系统奠定了坚实基础。它激励模型开发者不仅注重传统的检索准确率,还要关注模型对指令理解的灵活性和泛化能力,最终实现满足用户多样化需求的智能信息服务。总结来说,MAIR大规模多任务指令检索基准是新时代信息检索技术的重要里程碑。它赋予研究者一个前所未有的多元评测环境,揭露了当前模型的优势与不足,从而推动指令驱动检索技术持续迈向成熟与创新。随着技术的不断演进,我们期待基于MAIR的检索模型在更多实际应用中发挥巨大价值,提升用户信息检索体验,激发人工智能在信息时代的无限潜能。
。