随着大数据时代的来临,海量文件的快速高效处理成为企业和开发者面临的重要挑战。传统的文件处理方式常常因内存占用过高、处理速度缓慢而导致性能瓶颈。UIT(Universal Information Terminal)作为一款专注于云端环境的文件处理库,凭借其卓越的性能表现、模块化设计和低内存占用,正成为应对大规模文件处理需求的强大工具。 UIT的设计理念主要围绕四大核心优势展开。首先是卓越的性能优化。UIT精心设计了文件处理的各个环节,特别是采用了流式处理和并行执行策略,在保证处理速度的同时极大地减少了内存的占用。
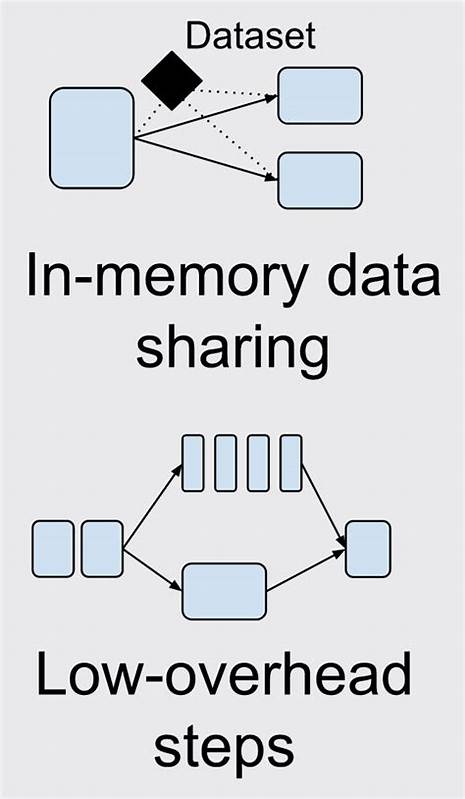
这使其能够轻松应对数百万甚至数千万级别的文件数据,而不会出现内存溢出或处理延迟严重的情况。 其次,UIT采用了高度模块化的架构设计,使得整个文件处理流程可以拆分成独立的功能单元,每个单元负责不同的处理任务。例如,文件的摄取、过滤、转换和最终输出都由不同的模块承担。这种设计不仅让系统具备极强的扩展性,也方便开发者根据具体需求灵活组合和定制处理流程,实现个性化的数据处理方案。 第三个显著特色是低内存消耗。传统文件处理通常会一次性加载大量数据至内存,不仅不适合云端这种资源受限的环境,也限制了处理规模。
而UIT利用浏览器和服务器上普遍支持的Streams API,支持数据的流式传输和处理,从而大幅度降低单次处理所需的内存资源。得益于此,UIT能够在如Cloudflare Workers等轻量级服务器环境中稳定运行,极大地拓展了其应用场景。 最后,UIT支持丰富的输入输出格式,适配多种文件类型和数据结构。无论是压缩包ZIP文件、多文件FormData格式,还是结构化的JSON和Markdown文件,UIT都能高效处理并实现相互转换。这种灵活的数据模态转换能力为开发复杂的云端文件处理流水线提供了坚实基础。 具体来看,UIT提供了一系列可组合的核心模块,每个模块专注于某一特定处理阶段。
例如,uithub.ingestzip模块能够高性能地将ZIP文件摄取并转换为标准化的FormData格式,方便后续处理模块进行操作。uithub.merge模块支持将多个FormData流合并为单一数据流,这对于从多源数据集合并文件时极其实用。 过滤与转换则是通过专门的filter/transform模块实现,允许开发者基于路径、文件内容等多维度条件对文件进行筛选和内容修改。该过程仍旧采用流式处理方式,保证效率与内存占用最优化。处理后的文件可以通过uithub.outputmd或uithub.outputzip等模块导出为Markdown文档或ZIP压缩包,满足不同场景的存储与传输需求。 值得一提的是,UIT不仅支持本地和服务器环境的运行,还与Cloudflare Workers等无服务器计算平台高度兼容。
由于其设计充分利用了流处理和模块化思想,使得每个模块都可以单独部署,实现分布式处理架构。这种方式不仅提升了容错能力,也方便按需扩展计算资源,充分发挥云计算的优势。 在安全性方面,UIT也做了细致考量。通过uithub.otp模块生成一次性密码(OTP),有效最小化了身份验证密钥在模块间传递的暴露风险,保证了数据处理过程的安全可靠。 此外,UIT还遵循统一的协议规范,即UIT协议。该协议定义了模块间如何协作,尤其是数据格式和消息头的标准化处理。
UIT通过标准FormData头部以及自定义头部传递额外信息,使各模块能在不破坏数据结构的前提下,传递错误标记、过滤结果等扩展信息,增强了模块间的互操作性和调试能力。 作为一个开源项目,UIT目前正在积极发展插件生态,鼓励社区开发者贡献各种文件过滤和转换插件,进一步拓宽其功能边界。项目文档详尽,配套教程和示例丰富,确保即使是初学者也能快速上手并参与到模块开发和定制中。 面对日益增长的云端数据处理需求,UIT以其高性能、模块化结构及低内存特性,为大规模文件处理提供了切实可行的解决方案。无论是需要快速处理海量资源的企业用户,还是追求高效灵活开发环境的技术团队,UIT都能提供强有力的支持和保障。未来,随着更多模块和插件的加入,UIT有望成为云计算时代文件处理领域的重要基石。
总的来说,UIT通过创新的架构设计和对现代云环境的深度适配,突破了传统文件处理工具的性能和资源限制。其强调流式、并行和模块化的原则,让用户能够在低内存环境下实现高效、可扩展的文件处理流水线。不论是数据摄取、文件合并、内容筛选还是结果输出,UIT都能确保高效执行并保持灵活的扩展性,极大提升业务效率与用户体验。随着云技术和无服务器计算的发展,UIT的应用前景将越发广阔,值得每一位云端开发者和数据工程师深入关注和探索。