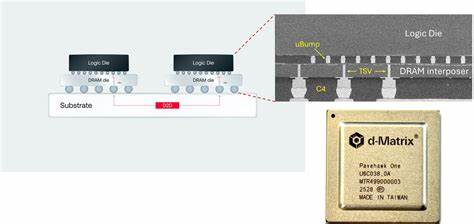
随着人工智能技术的飞速发展,尤其是在AI推理领域,传统的高带宽内存HBM(High Bandwidth Memory)正面临前所未有的挑战。美国初创公司d-Matrix带来了其突破性的3D数字内存计算技术(3DIMC),宣称这项新型3D叠层内存不仅在速度上可达HBM的十倍,更能实现同等性能下极大程度的能效提升。这一创新有望彻底改变AI推理的硬件基础,推动行业朝着更高性能、更低能耗的方向迈进。现今,HBM作为支持AI训练和高性能计算的关键内存技术,通过将多个内存芯片垂直叠加,实现更高的存储带宽和数据吞吐率,广泛应用于GPU和其他计算加速器中。然而,HBM虽在训练阶段占据优势,但其设计并非专门针对AI推理的特定需求,导致在推理环节表现受到一定限制。AI推理不同于训练,需要处理更为复杂且延迟敏感的计算任务,对于内存的访问延迟和带宽要求极高。
而HBM在功耗和带宽瓶颈逐渐显现,导致其扩展性和成本效益面临质疑。d-Matrix的3DIMC技术根本性地重新思考了内存与计算的关系,将计算功能直接集成于内存芯片内部,通过专门设计的数字内存计算逻辑实现对矩阵向量乘法等常见AI推理计算的高效执行。其创新点在于通过3D堆叠方式,将内存和计算模块紧密融合,内存访问速度大幅提升,同时大幅降低数据在芯片间传输所需的能量支出。该设计不仅解决了传统内存与计算分离导致的瓶颈,更为AI推理系统带来前所未有的能效优化。据d-Matrix首席执行官Sid Sheth介绍,当前的AI推理瓶颈不仅仅是计算能力的限制,更多体现在内存系统的性能和效率。随着模型规模的不断膨胀和推理任务数量的持续增长,HBM的成本和功耗将成为严重的制约因素。
3DIMC正是为了打破这一障碍而生,通过极致低延迟和高带宽的设计,显著提升AI推理性能,且在功耗方面可比现有方案降低达90%。目前,d-Matrix已经在实验室成功测试了首个名为Pavehawk的3DIMC硅片,展示了其优越的性能指标。未来的产品如Raptor计划以更完善的芯片组和模块化设计进一步巩固3DIMC对HBM的性能优势,目标是在推理任务中实现10倍速度提升的同时,降低能耗,令大规模数据中心和边缘计算更具成本效益。此外,这种技术革新反映了半导体行业对细分应用场景硬件优化的趋势。AI训练和推理作为两种截然不同的计算范式,分别需要不同的硬件架构进行专门定制。此类任务专用内存的出现,有望缓解当前AI工作负载对于通用硬件的压力,助力产业链实现更高的效率和可持续发展。
从市场角度看,HBM目前由少数几家大厂 - - 如SK海力士、三星和美光 - - 垄断生产,价格高昂且供应紧张。根据业内预测,HBM市场规模预计将保持高速增长,但成本上涨也势必带来用户侧的采购压力。d-Matrix提出的3DIMC方案作为潜在替代方案,为寻求高性能但价格敏感的AI客户提供了新的选择。尽管专门为推理设计的内存技术存在一定的应用局限性,但面对推理任务占据云端工作负载一半以上的现实,定制化硬件的吸引力不容忽视。3DIMC解决方案的推出,也可能推动整个高性能计算生态系统进行更加细致的软硬件协同优化,进一步释放AI模型的潜能。在实现如此目标的过程中,产业界仍需面临设计制造工艺、芯片互联效率和生态系统兼容性等多方面挑战。
d-Matrix通过采用芯片组模型和硅中介层连接技术,有效缓解了传统3D堆叠中的信号完整性和散热问题,提升了系统稳定性和可扩展性。未来随着制造工艺的进步和更多技术整合的实现,3DIMC有望成为AI推理硬件中的关键突破。综合来看,d-Matrix的新一代3D叠层数字内存技术标志着AI推理硬件进入了一个新时代。它不仅解决了传统HBM架构在带宽、延迟和能耗方面的痛点,还开创了计算与存储深度融合的新范式。对于AI研发者、数据中心运营商乃至终端设备制造商而言,这意味着在未来的人工智能应用中,能够获得更高的性能提升和运行效率。随着技术的成熟和市场的接受度提高,3DIMC有望成为推动AI推理快速发展和产业升级的关键引擎。
未来,我们期待更多类似创新的内存技术问世,助力人工智能走得更远更稳,带来前所未有的智能体验和社会价值。 。