近年来,神经形态计算作为模拟人脑结构和功能的新兴技术,逐渐成为人工智能和高性能计算领域的研究热点。与传统基于GPU的计算架构相比,神经形态系统具备显著的功耗优势和更适合模拟神经网络信号传递的低延迟特性,加速了AI模型的高效推理和训练。作为该领域的先驱之一,德国SpiNNcloud公司的SpiNNaker2系统近日完成了在美国桑迪亚国家实验室的部署,标志着神经形态计算技术迈入了实际应用阶段。桑迪亚国家实验室长期以来致力于推动未来计算技术发展,尤其关注神经形态架构与传统高性能计算(HPC)的融合。去年,他们引入了采用Intel Loihi 2芯片的Hala Point系统,用于能效比比较实验。今年全面启用的SpiNNaker2系统,进一步丰富了其多元化计算平台生态,支持更广泛的AI应用场景。
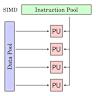
SpiNNaker2的硬件架构依托高度并行的Arm Cortex-M4F处理器核心,单芯片集成了152个低功耗处理单元。这些芯片通过高速互连构成24块板卡,整套系统总计拥有1152颗芯片,能够模拟大约1.75亿个神经元,是全球依托类脑神经网络原理建立的最大型计算平台之一。各处理单元通过环状和网状拓扑结构实现紧密连接,确保信号传递路径最短且通信效率最高。对于复杂神经网络的模拟和事件驱动的计算任务,SpiNNaker2不仅能高效调度各处理器,还能实现微观层面的路径隔离,这是传统GPU在多线程处理模式下难以达到的精细控制。相比近年来热门的电压脉冲型“尖峰神经元”芯片,SpiNNaker2突出的优势在于其高度灵活的可编程性,既支持事件驱动的神经元仿真,也兼容主流的深度神经网络(DNN)架构。这样,用户能够在同一平台上运行神经符号模型,实现神经网络与符号推理的有机结合,极大增强应用场景的多样性。
这一特色尤其适合包含推理逻辑和规则层面的复杂人工智能任务。Spnnaker2在能效上的卓越表现尤为引人瞩目。官方数据显示,其能效比传统GPU提升了18倍,未来发布的SpiNNext版本计划达到78倍。如此巨大的能耗优化不仅降低了运行成本,也为长期部署和边缘计算环境打开了可能。尤其在当前AI模型训练和推理普遍面临巨额电力需求的背景下,能效优势成为神经形态计算技术凸显的核心竞争力。桑迪亚国家实验室计划利用SpiNNaker2系统开展多项前沿研究,包括大规模药物分子发现。
通过部署成千上万的小型多层感知器(MLP)在每个芯片上,系统可以极度并行地执行分子结构模式匹配和患者数据分析,大幅提高药物筛选效率。此外,SpiNNaker2在解决经典的组合优化问题中也表现出卓越能力,支持量子不等式二次无序二进制优化(QUBO)及复杂的随机算法,适合调度、物流和复杂系统仿真等领域。这些应用的共同点在于均需大规模并行且高效的计算资源,而SpiNNaker2正有效满足了这一诉求。未来SpiNNcloud公司计划结合动态稀疏性技术进一步提升SpiNNaker系列在生成式AI和机器学习领域的表现。动态稀疏性指的是仅激活神经网络中部分子通路进行计算,极大降低资源消耗。SpiNNaker2基于事件驱动的通信机制和精细路径隔离能力,有望支撑高稀疏度的混合专家模型(Mixture of Experts),在不牺牲准确度的前提下实现计算成本的大幅降低。
相比传统为密集计算优化的GPU架构,其硬件灵活性显著。作为全球受关注的神经形态计算系统,SpiNNaker2正面临包括Intel Loihi和IBM NorthPole等竞争对手的挑战。然而,SpiNNaker2依托强大的可编程性和顶尖的硬件设计,无疑具备独特优势。尤其是其基于广泛成熟的Arm微处理器内核设计,更易吸引软件生态和开发者关注。随着算力需求不断攀升,能源效率成为制约AI及HPC发展的关键瓶颈,SpiNNaker2有望开辟节能且高效的新范式。桑迪亚实验室此次部署展示出神经形态计算正逐步从研究走向产业化应用。
系统已进入理想的测试与优化阶段,未来或将在智能推理、边缘处理、复杂优化、生命科学等多个领域发挥关键作用。中国乃至全球的AI产业,应密切关注这类技术的发展动向,抓住变革机遇,推动自主创新与跨学科融合。总体而言,SpiNNaker2不仅仅是一台计算机,更象征着类脑智能计算的重要进阶,是人工智能技术通向高效、灵活与节能发展道路的里程碑。未来几年,它的实践成果与生态构建,将直接影响神经形态计算及下一代AI硬件的走向。桑迪亚国家实验室和SpiNNcloud的合作为整个科技界提供了宝贵的示范效应,有望引领全球AI计算迈入新纪元。