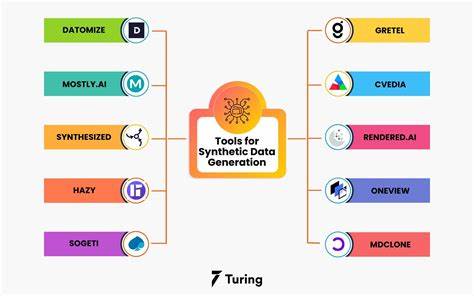
在当今数字化快速发展的时代,数据的获取和处理显得尤为重要。然而,现实世界中的数据收集常常面临诸多挑战,比如隐私和安全问题,以及获取数据的费用和风险。为了解决这些问题,合成数据的概念应运而生。合成数据是通过生成算法创建的类似真实世界的数据,这样在数据保护、成本和时间方面都带来了显著的优势。 随着生成性人工智能(Generative AI)技术的发展,出现了众多工具,它们专为合成数据的创建而设计。以下是20款值得关注的生成性AI工具,帮助用户高效地创造合成数据,以满足不同的需求。
首先,我们要提到的是“Mostly”。作为一个知名的合成数据平台,Mostly在金融、零售、通信和医疗等行业广泛应用。该平台的亮点在于它生成的数据严格遵循隐私和数据保护法规,如GDPR和CCPA。同时,Mostly的用户界面围绕自然语言构建,用户可以通过与其进行类似聊天的方式来查询数据,极大地方便了操作。此外,Mostly还设有保护机制,以防止在生成合成数据时引入偏见。 接下来是“Gretel”。
Gretel以其友好的用户体验而闻名,用户无需具备深厚的编程技能就可以创建表格式、非结构化和时间序列数据,适用于各种分析和机器学习工作流。Gretel也提供了大量的连接器和API集成,确保与大多数云服务和数据仓库基础设施兼容。活跃的用户社区也为用户提供了必要的支持和帮助。 在医疗领域,“Synthea”是一款开源的免费工具,专门设计用于创建合成患者数据。Synthea可以为不存在的患者生成完整的医疗记录。因此,医疗研究人员在解决复杂的卫生问题时,可以避免使用真实患者数据所带来的隐私和伦理问题。
这一工具极大地推动了医疗数据的研究与分析。 另外,“Tonic”是一个非常全面的平台,旨在生成真实、合规和安全的合成数据。Tonic主要针对软件和AI开发,除了合成数据生成外,它还提供了对真实数据的去识别化处理。用户可以选择在本地部署或在云环境中访问,并且该平台设计用于与所有常见数据库集成。 “不容忽视的还有Faker”,这个针对Python和JavaScript等多种编程语言提供的库,允许用户创建虚假的数据,比如电子商务购买行为或金融交易等。尽管需要一定的编码知识,但Faker在创建可以用于训练推荐引擎和欺诈检测算法的虚假数据方面,已经吸引了众多用户的青睐。
除了这些工具,市场上还有许多其他不错的合成数据生成工具。比如,Broadcom的CTA Test Manager可以创建技术复杂度较高的数据集;BizData X则通过合成数据生成简化了数据掩码和匿名化过程;Cvedia专注于计算机视觉和视频分析,运用合成数据提升模型性能;Datomize利用动态验证工具确保生成的数据尽可能真实。 还有GenRocket,这是一款专注于企业可扩展性的动态数据生成工具,主要用于软件测试;Hazy则被誉为全球首个合成数据市场,非常值得关注;K2View能够为训练机器学习模型生成数据;KopiKat是一款无代码的数据增强工具,旨在提高隐私性和神经网络性能;MDClone则专注于医疗行业的数据生成。 最后,Simerse专注于创建计算机视觉应用的合成训练数据;Sogeti被称为“数据放大器”,能够根据现有数据的特征和关联生成类似真实的数据;Synthetic Data Vault是一个开源的机器学习模型,能够生成高容量的合成数据;Syntho则提供自助的数据生成服务,帮助企业实现洞察和决策;YData致力于自动化合成数据生成,提升生产力和AI模型的表现。 随着技术的进步,这些工具的出现不仅降低了数据收集的成本,还解决了许多传统数据生成方法无法克服的问题。合成数据的使用前景广阔,涵盖了金融、医疗、AI开发和零售等多个领域,革命性地推动了这些行业的发展。
总的来说,生成性AI工具的出现为数据科学家和研究人员提供了强大的助力,帮助他们在保护隐私的同时,创造出高质量的数据。这些合成数据工具正在不断演进,未来将为我们带来更多的可能性。随着对数据的需求不断增长,合成数据的应用场景也将更为广泛,意图重塑传统数据处理的方式。 在探索合成数据的过程中,我们必须保持对技术进步的关注,充分利用这些工具的优势,同时谨慎处理数据隐私与安全问题。合成数据工具的前景令人期待,未来的AI与数据科学领域将会更加强大和多元。