在统计学和数据分析领域,回归分析是一种用于研究变量之间关系的重要工具。线性回归作为其最基础且广泛应用的方法,主要依赖于对误差的处理方式,不同的误差处理方法会直接影响模型的表现和预测准确性。其中,最常见的两种方法分别是最小二乘法(Least Squares)和最小绝对偏差法(Least Absolute Deviations)。理解这两种方法的不同原理和优势,对于选择合适的回归模型具备重要意义。最小二乘法是进行线性回归时最经典且被广泛采用的方法。其核心思想是通过找到使预测值与实际观测值之间的差值平方和最小的模型参数,从而保证整体误差的最小化。
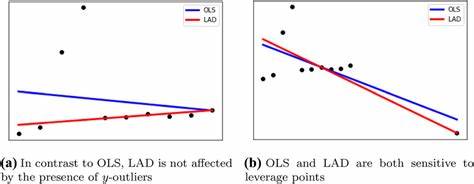
这种方法简单且计算方便,能够对误差进行较好地平均化处理。其数学形式是最小化所有残差的平方和,即优化参数使得yi与fθ(xi)之间差值的平方总和达到最小。最小二乘法的直观优势在于,平方差的计算惩罚了较大偏差,使得模型更倾向于减少大误差的出现,这也保证了其对整体数据的良好拟合能力。另外,最小二乘法对应的是假设误差服从正态分布,也使得其在很多实际应用中具有统计上的合理性。然而,最小二乘法也存在一定的不足。由于平方项放大了大误差的影响,模型对异常值(Outliers)特别敏感,单个极端点可能导致模型参数发生较大偏移,降低模型稳健性。
除此之外,平方的非线性性质也可能使得优化过程对初始条件较为依赖。相比之下,最小绝对偏差法是一种更为稳健的回归方法。其基本思路是通过最小化预测值与实际观测值之间绝对差的总和,从而求得最优的模型参数。数学表达上即是最小化所有残差的绝对值之和。与最小二乘法的平方差不同,绝对差忽略了误差的平方放大效应,使得模型对大偏差有着更低的权重。这一性质使得最小绝对偏差法能够有效抵抗数据中的异常值或噪声干扰,从而获得更稳定的估计结果。
可以说,这种方法优化的是中位数误差而非均值误差,从统计角度看更适合具有不对称分布或异常值的数据集。尽管最小绝对偏差方法在鲁棒性方面具有明显优势,但其计算复杂度一般高于最小二乘法。绝对值函数在数学上是非光滑的,这使得其导数不存在某些点,导致优化问题更难求解,需要借助线性规划或迭代算法来获得参数估计。此特点限制了它在超大规模数据或者实时系统中的应用。在数学求导层面,最小二乘法使得误差平方和关于参数的导数为零,确保解的解析性和稳定性。而最小绝对偏差这类包含绝对值的目标函数,其导数在零点处不存在,解决方案往往需要采用分段函数处理或者利用子梯度方法实现,这对算法设计提出了挑战。
在实践中,数据往往存在多种特性,如误差分布不同、异常值数量不一。一般来说,当数据误差接近正态分布且异常值较少时,最小二乘法由于其效率高和理论简单,依然是首选模型。然而当数据包含明显异常值或误差分布具有厚尾特征时,采用最小绝对偏差方法能够更好地反映数据结构,避免模型被极端点影响。除此之外,理论分析也指出,最小二乘法对应于最大似然估计基于正态分布的假设,而最小绝对偏差对应于误差遵循拉普拉斯(双指数)分布时的最大似然估计。这一统计解释为两者的选择提供了概率基础,有助于理解在不同数据背景下应用哪种方法更科学。在现代机器学习领域,这两种方法依然是许多复杂模型的基础。
其思想拓展到正则化、稀疏回归甚至深度学习损失函数中。根据具体应用需求和数据特征,研究者和工程师往往会结合两者特点,对损失函数进行加权组合或采用更复杂的鲁棒统计方法。如Huber损失函数即结合了两种方法的优点,在误差较小时使用平方差,误差较大时转为绝对差,从而兼顾了效率和鲁棒性。总结而言,最小二乘法与最小绝对偏差分别代表了线性回归中两种不同的误差优化理念。前者注重误差的平方和,强调均值优化,在理想无异常点数据中表现优异;后者强调误差的绝对值和,更关注中位数优化,适用于存在噪声和异常值的复杂数据。选择合适的方法需要结合具体数据的特点和应用场景,合理权衡计算效率和稳健性。
深入理解这两种回归方法的机理与优劣,对于从业者提高模型性能、解释能力和应用效果均具有重要意义。