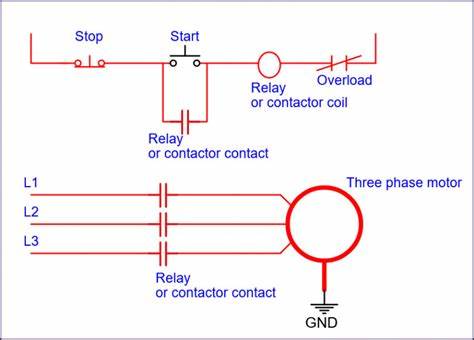
随着人工智能技术的迅猛发展,特别是大型语言模型(LLM)的广泛应用,各行各业都在探索其潜力和边界。自由开源软件(FOSS)作为软件生态中的重要组成部分,其知识传播和文档建设一直备受关注。在这一背景下,LLM是否适合用来撰写FOSS相关书籍成为一个备受争议的话题。本文将从多个角度深入探讨LLM参与FOSS书籍写作的可能性、优势与风险,以及对未来开源文化和技术发展的影响。 首先,LLM的出现为知识生成带来了革命性的机遇。它们可以快速理解不同领域的文本信息,通过大规模数据训练学习术语、结构和知识逻辑,从而生成符合语境要求的连贯内容。
对于FOSS领域,众多项目和技术文档的碎片信息可以通过LLM整合成系统性书籍,有助于降低初学者的入门难度,加快知识普及速度。更重要的是,LLM能够根据最新的开源技术动态实时更新内容,弥补传统书籍更新滞后的短板。 然而,FOSS的核心价值之一是社区驱动和知识共享的透明性。书籍作为知识传播的重要载体,其准确性、权威性和伦理考量尤为关键。LLM虽然在生成文本方面表现优异,但其训练数据来源复杂且庞杂,可能包含不准确或过时的信息。若未经充分审核直接生成FOSS书籍内容,可能会传递误导性信息,影响读者的学习效果甚至导致项目实施风险。
因此,依赖LLM独立完成FOSS书籍写作存在相当的隐患。 此外,FOSS社区的文化特点强调贡献者的身份识别和责任归属。传统的书籍作者往往是某一领域的专家或经验丰富的软件开发者,他们对某些技术细节和项目演进有深入理解。而LLM作为机器生成内容的工具,缺乏主观意识和责任感,难以承担内容准确性和道德规范方面的责任。这种角色定位差异在出版和法律层面引发了关于作者权利、版权归属和内容审核的复杂问题。 不过,LLM在辅助FOSS书籍编写中的优势不容忽视。
它可以作为写作助手,为作者提供初步内容草案、技术实例和语言优化建议,节省大量时间和精力。编辑者可以基于自动生成的内容进行甄别、补充和修正,保证书籍质量与实用价值。这种人机协作模式或许是未来FOSS知识传播的理想路径,实现效率与质量的平衡。 未来,随着LLM技术的不断进步,尤其是在理解语义准确性、逻辑推理能力及事实验证机制的强化,将有望逐步解决目前面临的准确性和责任问题。开源社区也可能开发专门针对FOSS文档的训练数据集,提升生成内容的专业度和可靠性。另外,建立透明的内容审核体系和社区反馈机制,是保障LLM生成书籍质量的关键环节。
总体来看,LLM作为自由开源软件书籍的独立作者尚需克服诸多技术和伦理障碍,但其作为辅助工具的价值日益明显。正确运用LLM技术,将帮助FOSS社区加速知识更新和普及,降低学习门槛,推动开源文化的广泛传播。同时,在尊重社区规则和保护知识产权前提下,推动人工智能与开源协同发展,能打造更加开放、高效且创新的未来软件生态环境。 。