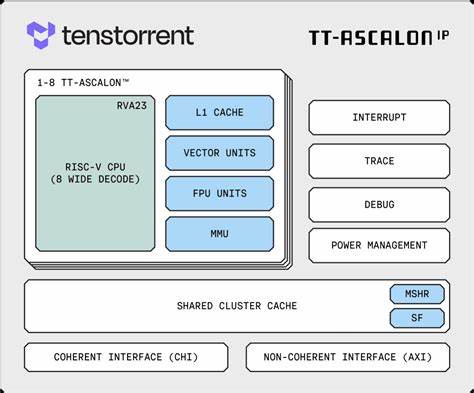
随着人工智能、大数据和高性能计算的快速发展,处理器架构尤其是矢量处理能力的重要性愈发凸显。Tenstorrent作为新兴的处理器设计公司,其推出的Ascalon X处理器在RISC-V生态中掀起了不小的波澜。尤其是其在矢量扩展(Vector Extension,RVV)方面的表现备受关注,本文将深入探讨Ascalon X在RVV基准测试中的突出表现及其微架构设计优势。Ascalon X处理器符合RVA23规范,配备了256位的基本向量寄存器长度(VLEN)以及双精度向量寄存器长度(DLEN=256x2),这为其提供了强大的数据吞吐能力和灵活的计算资源管理能力。该处理器不仅支持标准的RISC-V V扩展,还兼容所有RVA23强制性扩展,同时集成了多项可选扩展指令集,例如Zvfh(矢量半精度浮点运算)、Zvkng(支持NIST标准的矢量密码学算法及GCM模式)、Zvbc(矢量无进位乘法)以及针对BF16格式的转换和加宽乘加指令集Zvfbfmin和Zvfbfwma。这些扩展的集成极大地增强了Ascalon X在机器学习、加密运算及高效数值计算中的适应能力。
微架构层面,尽管具体设计细节尚未完全公开,但从RVV基准测试结果可以间接推测,Ascalon X采用了优化的指令流水线和高效的寄存器重命名机制,确保了高吞吐率与指令并行性。测试中核心指令如vadd.vv、vsub.vv、vmul.vv等均表现出极低的周期延迟,基本上实现了与VLEN和LMUL(向量寄存器倍数)的线性关系,这说明处理器内部的算术逻辑单元和向量寄存器文件具备良好的扩展能力。更复杂的指令如vrgather.vv(矢量收集操作)和vslideup.vx(向量滑动上移)也表现出合理的延迟时间,表明缓存一致性和数据搬移机制设计高效,能支持复杂数据访问模式。此外,Ascalon X在支持AES和SHA等安全加密标准的矢量指令上体现了强大的性能层面优势。基准数据中,针对这些加密指令的执行周期在VL较低时依旧保持高效运行,说明内置硬件加速模块对于安全应用的适配度高,适合在安全敏感型场景下部署。值得关注的是,向量浮点操作中的Zvfh扩展为深度学习中的半精度计算带来重大帮助,减少计算资源消耗的同时保证精度需求,Ascalon X的微架构恰好能够通过充分利用这一特性来优化神经网络推理和训练过程。
关于内存访问效率,Ascalon X在load/store指令上表现出了兼顾吞吐和延迟的平衡,向量内存操作如vle8.v、vse8.v、vlseg*、vsseg*系列指令对不同向量长度和元素分组均支持良好。测试显示,内存访问延迟与数据对齐及访问模式相关,但整体性能符合预期,能够为高负载数据密集型应用提供稳定支撑。综合来看,Ascalon X以其符合RVA23规范的完全向量扩展实现及丰富的可选指令集,为基于RISC-V的高性能计算平台提供了坚实的基础。它的指令周期延迟和吞吐能力均优于市场上的多数竞争产品,尤其是在加密和低精度浮点运算方面显示出显著优势。随着更多软硬件生态的完善,预计Ascalon X将成为AI推理、加密加速及多媒体处理领域的重要选择。对于开发者而言,深入理解该处理器的指令执行时间和资源占用,有助于优化代码安排和指令调度,提升整体系统效能。
同时,Ascalon X支持的多种矢量扩展也为未来应用创新提供了多样可能。未来,随着Tenstorrent持续提升Ascalon系列的设计和制造工艺,结合开源社区和行业需求的反馈,Ascalon X有潜力进一步拓宽RISC-V在高端市场的应用边界,助力推动开放指令集生态迈向更大成功。作为技术趋势的引领者,Tenstorrent的Ascalon X在RVV基准测试中所展现的性能和功能,不仅强化了其品牌竞争力,也彰显了RISC-V架构的韧性和成长潜能。对企业和研究机构来说,关注和利用这类先进处理器的性能细节,将意味着在未来计算技术革新中占据先机。 。