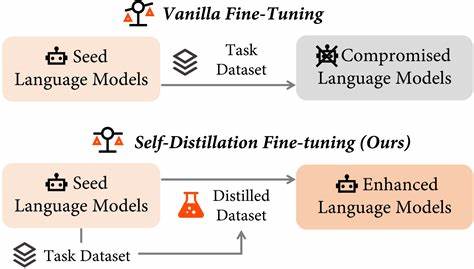
随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理领域展现出强大的能力。从撰写文章、回答问题,到代码生成和语言翻译,LLM已经成为推动智能化时代的重要引擎。然而,如何进一步提升这些模型的性能,特别是在缺乏高质量人工监督数据的情况下,成为了行业内亟待解决的难题。传统的微调方法依赖于人工标注和监督数据,既成本高昂又难以匹配模型自身日益增长的超人类能力。为此,一种创新性的无监督自我微调策略——Internal Coherence Maximization(ICM,内部一致性最大化)应运而生,为LLM的自我优化开启了新的篇章。Internal Coherence Maximization是一种基于模型自生成标签的无监督微调算法。
它的核心理念是通过最大化模型内部预测的一致性,提高模型在自身生成数据上的准确性和可靠性。具体来说,ICM不再依赖外部的人工标注,而是利用模型对任务答案的多次推断,自动筛选内在共识较高的结果作为“伪标签”,进而微调模型参数。这不仅降低了人工干预成本,也让模型能够自主发现更优解,从而增强其推理和理解能力。在实验层面,ICM已经在多个权威测试中表现出色,包括GSM8k-verification、TruthfulQA和Alpaca奖励建模等任务。令人瞩目的是,ICM的无监督微调效果甚至能够媲美或超越基于黄金监督数据的传统微调策略,且明显优于依赖人类众包标签的训练方式。这一突破性进展意味着,在面对部分超人类级别的任务时,人工监督不再是限制模型发展的瓶颈。
ICM的无监督特性使其在更复杂、更开放的应用场景中具备广泛的适应性和扩展性。此外,ICM在前沿大型语言模型的训练过程中也展现出巨大潜力。研究团队通过基于ICM训练出的无监督奖励模型,结合强化学习策略,进一步驱动了Claude 3.5 Haiku助手的自我优化。结果表明,该助手及其奖励模型在多个性能指标上显著超越了传统人类监督训练版本,体现了自我微调技术在实际商业化产品中的应用前景。无监督自我微调为实现真正智能的语言模型开辟了新路径。它不仅保障了模型能够在缺乏高质量人工标签的环境下持续进化,还促进模型内部一致性与可信度的提升,为解决机器学习中的标注数据稀缺难题提供了新思路。
这一技术革新将进一步推动LLM在教育、医疗、法律、科学研究等多领域的落地应用,更好地服务于社会和产业发展。展望未来,Internal Coherence Maximization及相关无监督自我微调方法或将成为大型语言模型调优的主流范式。随着算法的不断优化和计算资源的升级,模型自主发现知识和自我修正的能力将进一步跃升,带来更优质、更可靠、更具创新性的人机交互体验。同时,这也对人工智能伦理和监管提出了新挑战,如何保证自我微调过程中模型行为的安全性和公平性,将成为学界和产业界关注的重点方向。综上所述,无监督的Internal Coherence Maximization方法以其高效、低成本和自适应的优势,正在引领大型语言模型迈向无监督时代的自我进化。它不仅破解了传统训练架构的瓶颈,更赋予了模型自主提升的智慧,标志着人工智能迈入一个崭新的篇章。
在未来智能社会中,ICM技术有望成为驱动语言模型不断突破极限的关键引擎,助力人工智能实现更为广泛和深入的社会价值。