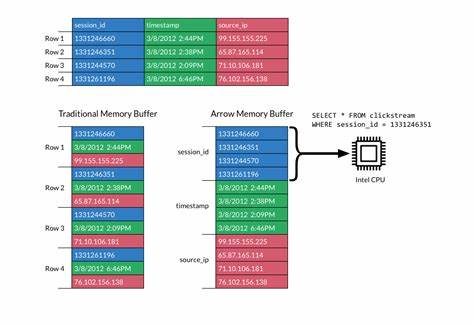
随着大数据和云计算的快速发展,列式数据格式在数据存储和分析领域变得越来越重要。Apache Arrow作为一种高效的内存数据格式,因其零拷贝以及跨语言的高性能特性,逐渐成为业界的热门选择。然而,为了更好地在C++生态中利用Apache Arrow,开发者迫切需要一种更加现代化且符合C++20标准的API设计。Sparrow应运而生,成为连接现代C++与Apache Arrow的桥梁。 Sparrow是一个以C++20为基础,专注于Apache Arrow列式格式的API实现项目。它通过提供符合现代C++习惯用法的接口,为开发者带来了前所未有的便捷性和高效性。
项目旨在简化Apache Arrow C接口的使用难度,同时增强代码的可读性和安全性。对开发者来说,Sparrow不仅仅是一个库,更是一种设计理念的体现。 Sparrow的核心优势在于其强大的类型安全和资源管理机制。传统的Apache Arrow C接口虽然功能完整,但在C++中直接使用时可能导致内存管理复杂及类型不确定性。而Sparrow利用C++20的新特性,如概念(Concepts)、范围for循环、模板化设计等,构建出直观且健壮的数组结构和数据转换接口,极大地减少了出错概率。 通过Sparrow,用户可以轻松创建和操作多种类型的列式数组,从基本的整型到复杂的嵌套结构,无需关注底层的指针管理和释放操作。
Sparrow自动管理这些细节,使开发者能够专注于业务逻辑的实现。尤其是在处理大型数据集和多线程环境时,安全和性能上的提升尤为突出。 另一个值得关注的方面是Sparrow对跨语言和跨平台的支持。它不仅封装标准的Apache Arrow C结构,还提供与第三方库兼容的接口,方便数据交换和集成。得益于其对主流编译器的支持(如Clang、GCC、MSVC等),Sparrow可以在多种操作系统和硬件架构上无缝运行,这对于现代云原生应用极为重要。 安装和使用方面,Sparrow支持通过mamba(或conda)等主流包管理器轻松安装,也可以从源码构建,满足不同开发环境的需求。
官方文档和示例代码丰富,尤其是对新手友好,使学习曲线变得平滑。项目团队不断推陈出新,活跃的社区和持续的贡献保证了项目的生命力和创新力。 在实际应用中,Sparrow被广泛用于金融数据处理、科学计算、数据分析平台以及人工智能模型的数据预处理环节。其高性能的列式数据访问接口能够显著提升数据管道的效率,降低延迟,从而加速整体数据处理流程。同时,代码的清晰性和维护性也随之提高。 对比传统的Apache Arrow C++接口,Sparrow更符合现代软件工程的设计原则。
它拥抱新标准、新工具,并且借助泛型编程和类型推导实现更简洁的代码结构。未来,随着C++的不断发展,Sparrow也将继续进化,为开发者提供更加灵活和强大的功能。 总结来看,Sparrow不仅是对Apache Arrow生态的重要补充,更是C++20时代数据处理技术的典范。它通过现代化的API设计,简化了复杂的数据格式交互,提升了开发体验与系统性能。无论是大数据开发者,还是系统架构师,Sparrow都值得深入了解和使用。随着数据驱动的应用场景不断扩展,Sparrow有望成为推动行业技术进步的重要力量。
。