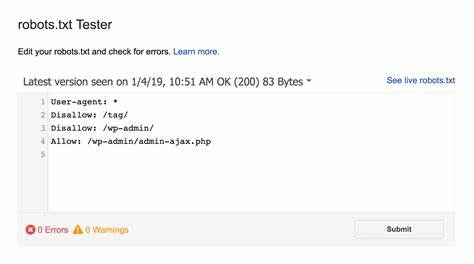
在网站管理中,robots.txt文件扮演着重要的角色,它决定了搜索引擎爬虫和其他自动化程序如何访问和抓取网站内容。很多站长初衷是通过严格的robots.txt规则来保护网站数据和隐私,禁止所有爬虫访问,以防止内容被未经授权爬取和利用。然而,实际操作过程中,这种“全盘封杀”的策略往往带来意想不到的副作用,尤其是在社交媒体分享和内容推广方面。最近,我亲身经历过一次关于robots.txt认知的转变,这次经历让我深刻意识到合理配置该文件的重要性,也对其对网站整体生态的影响有了更全面的理解。 起初,我出于保护博客原创内容的考虑,将robots.txt配置成禁止所有爬虫访问网站的规则。我的初衷很简单,希望杜绝任何自动化爬虫访问,以避免内容被盗用或遭遇其他潜在风险。
配置变更后,我发现网站本身在搜索引擎上的排名依旧稳定,似乎问题不大。然而,没过多久,随着对内容推广的需求增长,我开始频繁在LinkedIn等社交平台分享文章链接。令人困惑的是,发布的帖子竟然失去了链接预览功能,帖子的点击率和互动度也明显下降。起初我以为这只是平台自身的临时故障或算法调整,直到通过LinkedIn自带的链接检查工具——Post Inspector,才发现问题的根源竟然来自于我设置的robots.txt文件。 原来,我的robots.txt文件中直接禁止了LinkedIn爬虫访问网站内容,而这些爬虫正是负责抓取网页元数据,生成动态链接预览的关键。当社交平台获取不到网页中的Open Graph元标签数据,就无法自动生成包含标题、图片和描述的丰富预览,导致帖子在视觉呈现上失去吸引力,进而影响了内容传播的效果。
Open Graph协议是一种由Facebook推出的网页元数据标准,它允许任何网页通过指定特定的meta标签,成为社交网络中的“丰富对象”,以便平台生成具有吸引力的信息预览。常见的标签包括og:title、og:type、og:image和og:url,这些标签告诉平台网页的标题、类型、展示图片以及网址,从而增强内容的表现力。 这一经验让我深刻认识到,robots.txt的设置不仅仅影响搜索引擎蜘蛛抓取,事实上,各大社交媒体平台的爬虫同样依赖对网页的访问权限来获取必要的元数据。阻止这些爬虫,意味着放弃了在社交平台上展示优质链接预览的机会,也就在客观上降低了内容触达更多用户的可能性。 为了扭转这一局面,我对robots.txt进行了调整,专门为LinkedInBot开放访问权限,而其他非特定爬虫依然保持禁止。新配置允许LinkedInBot抓取网站内容以获取Open Graph元数据,从而恢复了链接预览功能。
此外,也意识到若未来计划在更多社交平台分享内容,应为相应平台的爬虫提供访问权限。通过更细粒度的管理,实现了保护内容和提升传播之间的平衡。 这次调整让我收获良多。首先,在网站爬虫管理上,简单粗暴的禁止策略往往忽略了互联网生态中的多样角色,包括搜索引擎、社交平台和其他第三方工具的需求。其次,对网站内容的展示效果,尤其是社交媒体上的丰富化呈现,依赖于爬虫能够顺利访问并解析网页的Open Graph协议标签。最后,合理了解和测试robots.txt文件的配置效果,确保不会阻断重要爬虫访问,是网站运营中的关键环节。
通过此次经历,我也认识到,作为站长应当持续学习网络协议、爬虫行为规范以及社交媒体的内容表现方式。只有全面理解这些技术底层逻辑,才能设计出既保证内容安全又实现高效传播的策略。robots.txt文件虽然简单,但在其中蕴含的权限管理逻辑直接影响着网站的搜索引擎表现和社交媒体互动。 此外,利用社交平台提供的工具,例如LinkedIn Post Inspector、Facebook的Sharing Debugger等,能够快速诊断链接预览相关问题,指出因爬虫阻止而导致的信息抓取障碍。将这些工具纳入日常内容推广流程,有助于及时发现和修正配置信息,避免用户体验和流量损失。 总结来看,robots.txt文件的配置需要权衡保护内容和开放资源之间的关系。
严苛的阻拦会影响网站的自然传播和用户互动,而适度的放行则能够加速内容影响力的扩散。务必切记,在调整robots.txt前进行充分的调研和测试,从多维度评估对搜索引擎、社交平台爬虫乃至普通访问者的影响。网络世界瞬息万变,只有不断校准站点策略,才能兼顾数据安全与商业价值,最终实现内容的最大化发挥。我的这次错误尝试也成为提醒所有网站管理者的宝贵经验:对技术细节的忽视,可能会引发意想不到的连锁反应,影响整个内容生态的健康发展。坚持学习,积极调整,互联网之路必将越走越宽。