随着人工智能技术的迅猛发展,大型语言模型(LLM)在自然语言处理等多个领域展现出强大的能力。然而,支撑这些模型的训练数据往往庞大且复杂,其版权和伦理问题也日益受到关注。传统上,许多LLM训练依赖于未经明确授权的大规模文本数据,这引发了对知识产权保护、隐私权和伦理合规的担忧。Common Pile v0.1作为一个旨在收集、整理并开放使用的8TB规模数据集,专注于公有领域和公开授权文本,正好填补了此类合规高质量数据集的空白。Common Pile v0.1囊括了来自30个不同来源的文本数据,涵盖了科学研究论文、程序代码、电子书籍、百科全书条目、教育教材以及音频转录文字等多个领域。多样化的数据覆盖有助于模型在各类真实场景下的应用表现更加稳健和准确。
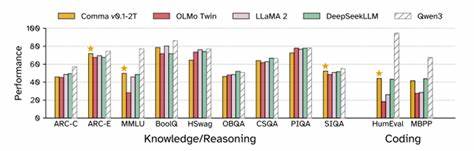
同时,数据源均基于公开授权,保证了使用的合法性和透明度,降低了潜在的版权风险。这一数据集的数据规模达到8TB,包含了1到2万亿级别的训练标记(tokens)。研究团队基于Common Pile数据集训练了两个7亿参数的语言模型,分别使用了1万亿和2万亿训练标记。这两款模型在多个自然语言处理基准测试中表现优异,能够媲美甚至超越包括Llama 1和Llama 2 7B在内的竞争对手,而且大部分这些对手都是使用未经授权的数据训练的。从技术角度看,Common Pile的发布为提升训练数据透明度和合规性树立了行业标杆。它不仅为开发者提供了一个开箱即用的、丰富的训练资源,也推动了对数据来源和授权状态的严谨审视。
此外,相关代码和训练脚本也一并开源,方便研究人员复现和进一步优化相关模型。从长远来看,依托Common Pile v0.1这类数据集,人工智能领域可以减少因非法使用数据带来的风险,建立更负责任、更可持续的训练机制。同时,公共领域和开放授权文本的大规模整合,有助于降低模型研发门槛,特别是使中小型研究机构有机会参与大模型开发,加速AI技术的民主化进程。此外,Common Pile在多样性和包容性方面的优势不容忽视。其内容包括多语言、多领域的文本数据,促进模型能够适应不同的语言环境和专业需求,提升其应用广度。这对实现真正通用的自然语言处理技术具有重要意义。
在合规性和版权保障之外,Common Pile也针对训练数据的质量进行了严格把控。通过精细化的数据清洗、去重及格式标准化处理,保障了训练数据的整洁度和一致性,从而提升了模型训练的效率和效果。综上所述,Common Pile v0.1的诞生为大型语言模型领域带来了新的风向标。它不仅解决了训练数据合规性的核心问题,也为进一步提升模型性能和多样化应用提供了坚实基础。期待未来更多类似的数据集能够涌现,共同促进开放、透明和负责任的人工智能生态系统建设。