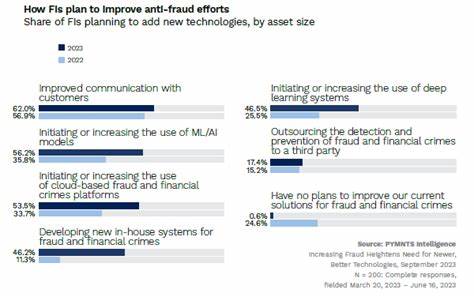
近年来,金融科技的快速发展给银行和金融机构带来了前所未有的挑战。其中,欺诈行为的频繁出现使得保护客户资产和维护金融安全变得尤为重要。据调研机构PYMNTS.com的最新报告显示,近一半的金融机构已开始采用深度学习系统来应对这一问题。本文将探讨深度学习在反欺诈方面的应用,以及其如何帮助金融机构提升安全性和效率。 首先,什么是深度学习?深度学习是一种机器学习的分支,旨在通过模拟人类大脑的工作方式来识别数据模式。通过构建深层神经网络,深度学习模型能够从大量的数据中提取特征,从而进行高效的分类和预测。
在金融行业中,这项技术特别适用于检测复杂的欺诈行为。 金融欺诈的形式多种多样,包括信用卡欺诈、身份盗用、洗钱等。这些欺诈行为的隐蔽性和复杂性使得传统的规则基础防御措施难以发挥效果。与此相对,深度学习系统能够通过分析历史交易数据及用户行为模式,建立动态的风险评估模型。这些模型不仅可以识别已知的欺诈行为,还能及时发现新型的欺诈手法。 一项深度学习模型能够自动从不断变化的数据中自我学习,随着时间的推移,其识别欺诈的准确性会不断提高。
例如,通过对用户消费习惯和偏好的细致分析,系统能够发现异常交易并及时发出警报。当一笔交易与用户的通常行为大相径庭时,深度学习系统可以快速判定其风险性并采取相应措施,如冻结账户或要求客户确认交易。 目前,越来越多的金融机构认识到深度学习在反欺诈中的巨大潜力。据统计,近50%的金融机构已在其防欺诈策略中集成了深度学习系统。这不仅提升了他们对欺诈行为的检测能力,还显著减少了误报率,使得客户体验得以改善。 采用深度学习技术的成功案例不胜枚举。
许多大型银行已经实施了基于深度学习的反欺诈系统,通过实时监控和分析交易数据,他们能够迅速识别并阻止可疑交易。例如,一家国际性的银行通过深度学习技术,在一年内成功减少了30%的欺诈损失。此外,这些系统还能在提升安全性的同时,减少人工审查的工作量,让工作人员能够将精力集中在更复杂的任务上。 然而,将深度学习系统应用于反欺诈并非没有挑战。首先,数据的质量和数量对模型的性能至关重要。金融机构需要确保所使用的数据完整且具有代表性。
此外,过度依赖机器学习模型可能会导致机构在应对新兴欺诈手法时缺乏敏感性。因此,保持人机结合的工作模式至关重要。 为了最大化深度学习技术在反欺诈中的效果,金融机构还需要建立有效的数据治理框架。这包括数据的采集、存储、处理和分析等各个环节。只有通过科学的数据管理,才能确保深度学习模型的有效性和可靠性。 随着技术的不断进步,未来的反欺诈系统将朝着更加智能化和自动化的方向发展。
例如,自然语言处理(NLP)结合深度学习技术,可以帮助机构自动化地处理客户反馈和申诉,提高服务的响应速度。通过多维度的数据分析,金融机构能够获得更全面的风险评估,从而采取更加精准的防欺诈措施。 总结而言,深度学习技术为金融机构打击欺诈行为提供了新的思路和工具。近一半的金融机构已经开始涉足这一领域,利用深度学习系统的优势提升反欺诈能力。在未来,随着技术的进一步发展与应用,我们可以期待金融行业将变得更加安全、智能,为客户提供更优质的服务。然而,在享受技术带来的便利的同时,金融机构也必须时刻保持警惕,做好风险管控,以应对潜在的新型欺诈挑战.。