随着人工智能的发展,生成式AI,尤其是大型语言模型(LLM),在自然语言处理、图像生成和自动化创作等领域展现了非凡能力。然而,尽管它们在模仿人类语言及认知活动方面取得了显著进展,生成式AI在构建和维护稳健、动态的世界模型方面却显现出严重缺陷。这种缺陷直接导致了推理失败、信息不准确和应用场景中的不可预测性,限制了其广泛应用的可靠性和安全性。世界模型,是指系统内部对现实世界中实体、事件、关系及规则的抽象和动态表示。它不仅帮助人类理解复杂情境,还支撑着各种认知活动,如推理、预测和决策。对人类和动物而言,世界模型是认知的核心;而对AI来说,拥有准确、可更新的世界模型意味着能够更好地模拟真实环境,实现智能推理和高效学习。
传统人工智能高度重视世界模型的设计。早期AI系统例如图灵设计的国际象棋程序,核心就在于对棋盘现状的动态建模。经典软件工程理论也强调算法与数据结构的结合,数据结构即指代这种世界模型的具体体现。相比之下,生成式AI尤其是大型语言模型,通常依赖于从海量文本数据中学习统计规律,却并未显式构建世界模型。它们的知识储存在分布式且高度复杂的参数空间中,而非明确的数据结构或符号表示。正是这种设计选择,虽然使它们能生成流畅自然的语言,但也造成了难以追踪和校正的黑箱效应,导致它们缺乏对现实世界状态的持续而准确的认知。
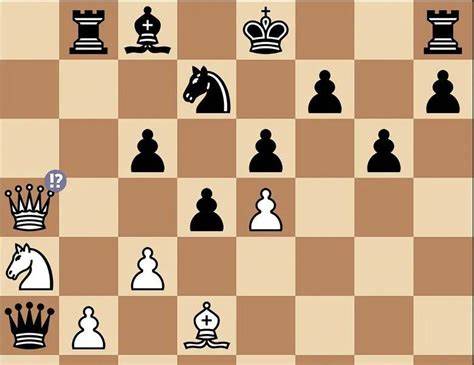
以国际象棋为例,尽管规则清晰且长期稳定,但主流的语言模型往往无法维持对棋局的动态追踪,从而导致非法走子、重复走法或棋局状态混乱等错误。它们凭借数据驱动的概率匹配能力对开局有所掌握,却无法基于实际棋盘动态推断中后期走法。这种现象揭示了生成式AI在模拟固定规则系统中缺乏世界模型所带来的根本局限。除棋类游戏外,在文本理解、对话生成、视频解析及图像创作等领域,生成式AI的世界模型缺失同样带来诸多问题。文本中信息的关联、事件的因果关系、情景的前后文推演都需要清晰且持续更新的内在模型,而这些模型恰恰是大型语言模型所缺乏的。由此产生的信息错漏、前后矛盾以及对细节的忽视,成为其在实际应用中频繁出现的误导和错误根源。
在视频理解任务中,先进模型往往无法准确捕捉关键事件的真实逻辑,如未能识别抢夺行为或行为的潜在意图,仅对表面场景进行描述,表现出认知的浅层和片面。类似的,图像生成技术时常出现不合常理的细节错误,比如动物多腿、人脸变形等,这些都体现出模型未能基于稳健的世界模型进行合理验证和调整。大型语言模型之所以难以建立稳健的世界模型,背后主要有两方面原因。其一,模型架构本身侧重于基于统计的关联性学习,而非符号化、结构化知识表达与推理。虽有试图通过神经符号混合或强化学习等方法改进,但尚未形成普遍有效的解决方案。其二,训练数据多样且复杂,却缺少系统化、多维度的现实世界动态信息更新机制,这阻碍了模型对环境变化和上下文的持续跟踪与整合。
尽管一些研究尝试通过外部数据库接入、知识图谱集成以及使用环境感知模块来弥补这一短板,但迄今为止效果仍有限。世界模型的缺失给生成式AI的安全性和可控性带来了严峻挑战。模型缺乏对自身输出的语义和事实一致性的深度把控,导致了频繁的“幻觉”“误导”甚至有害信息生成。例如,在法律、医疗、军事等关键场景中,错误信息可能导致灾难性后果,这对人工智能的部署和监管提出了更高的要求。建立具备稳健世界模型的AI系统,意味着不仅要捕捉表面语言信息,更需深入理解各领域知识、推理规则及其动态演变。近年来,认知科学和计算神经科学的相关理论被视为突破口。
结合符号推理与神经网络学习,探索多模态信息融合,设计持久记忆和动态更新机制,成为未来AI发展的重要方向。纵观生成式AI的发展历程,其既展现了非凡的语言表达和知识整合能力,也暴露了因缺乏隐式的世界认知模型而导致的深层次局限。正如知名认知科学家所指出,若没有稳健的认知模型和动态更新机制,任何智能系统都难以实现真正的理解和适应。随着技术进步和理论深化,未来人工智能有望融合概率统计学习与结构化世界模型设计,突破当前的认知瓶颈,推动智能系统走向更高水平的自主理解和推理。只有构建这样动态、可解释且可信赖的世界模型,生成式AI才能真正迈向通用人工智能的目标,在众多复杂且变化莫测的现实世界场景中发挥其应有的价值和安全保障。