近年来,人工智能领域尤其是大语言模型(LLM)的快速发展,正在深刻地改变我们的生产和生活方式。微软最新推出的BitNet b1.58 2B4T模型,以其突破性的原生1比特权重量化技术和卓越的性能表现,引起了行业的广泛关注。作为首个开源的原生1比特大语言模型,BitNet b1.58 2B4T不仅在参数规模上达到了20亿,而且在训练语料规模上突破了4万亿个tokens。这一进展不仅彰显了微软研究团队在模型压缩和效率优化上的深厚实力,也为未来更加绿色、高效的AI模型研发开辟了新路径。BitNet的架构基于Transformer框架,但经过了专门的BitLinear层改造,结合了原生的1.58比特权重量化方法和8比特激活量化。通过这种创新的量化策略,模型权重被限制在{-1,0,+1}的三值集合中,采用absmean方法实现动态前向传播量化,激活则通过absmax方法进行8位整数量化。
与传统的后训练量化不同,BitNet在训练阶段就全面采用这一量化机制,确保了其高效且精准的性能。微软还在模型中引入了旋转位置编码(RoPE)和平方ReLU激活函数(ReLU²),以及subln正则化技术,同时剔除了线性层和归一化层中的偏置项,这些设计细节共同保障了模型的稳定性和推理效果。BitNet b1.58 2B4T模型的最大上下文长度达到4096 tokens,能够胜任复杂的长距离依赖任务。虽然预训练语料主要以公共文本、代码和合成数学数据为主,微软建议对于超长上下文或专业领域任务进行额外的中间训练,以进一步提升模型的适应能力和表现。在训练过程中,BitNet经历了多阶段优化,从大规模预训练到监督式微调(SFT),再到直接偏好优化(DPO)与人类偏好对齐,展现出极具前瞻性的训练策略。令人印象深刻的是,模型在多项权威基准测试中的表现已不逊色于同级别的全精度开源模型。
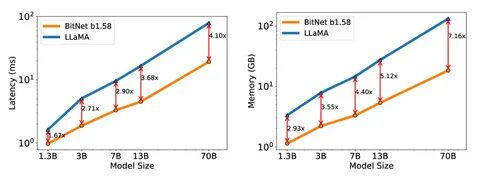
尤其在计算资源消耗方面,BitNet展现出极大的优势。与主流1-2亿参数规模模型相比,BitNet在推理时的内存消耗仅为400MB,CPU端解码延迟更是低至29毫秒,能耗指数远远低于竞品。这样的高效表现不仅降低了硬件门槛,还极大节约了能源消耗,实现了环保与性能的双赢。尽管模型已开源并支持在Hugging Face平台使用标准Transformers库,但微软特别强调,若想真正发挥BitNet架构带来的速度和能耗优势,必须使用官方提供的专门C++推理实现bitnet.cpp。这一专用代码库通过高度优化的计算内核,最大程度地利用了原生1比特权重量化的节省潜力,满足了实际工业场景对快速、低延迟推理的需求。目前,BitNet在英语文本生成和对话领域表现尤为优异,同时也支持指令调优和多轮会话功能。
其采用的LLaMA 3 Tokenizer不仅词汇量巨大达12.8万个,还能更好地处理复杂输入,提升生成文本的自然流畅度。尽管如此,微软提醒用户,该模型目前仍存在一定局限性。例如模型在非英语语种和某些专业领域的支持较弱,也可能出现偏见或误导性内容,尤其是在敏感的选举相关查询上表现尚不稳定,需谨慎验证相关信息。微软在公告中郑重声明,BitNet b1.58 2B4T主要面向科研开发,暂不建议直接用于商业或现实世界的关键应用场景。用户应结合实际需求,合理评估模型的风险与价值,避免盲目依赖。展望未来,BitNet开创的原生1比特LLM技术无疑为大规模模型的可持续发展树立了标杆。
随着硬件和软件生态的完善,未来更多基于轻量化量化方案的AI模型有望实现普及部署,突破现有算力瓶颈,推动智能应用走向更广阔的领域。总结来看,微软BitNet b1.58 2B4T凭借其独特的1.58比特量化权重和创新的训练体系,以2亿参数规模打破了性能与效率之间的平衡壁垒。它不仅代表了当代大语言模型研究的前沿,更彰显了人工智能绿色计算的未来趋势。对于业界专家、研发人员乃至AI爱好者而言,深入了解BitNet带来的技术革命,洞悉其性能优势与潜在局限,都是未来技术选型和创新应用中的重要参考。随着该模型及其相关工具链不断完善,我们有理由相信,一个高效、环保且功能强大的新时代大语言模型生态正在悄然成型,推动人工智能走向更加普惠和智能的未来。