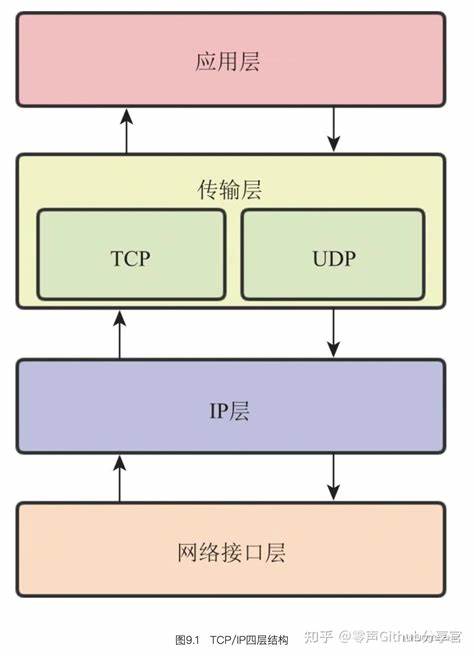
在机器学习模型开发过程中,特征选择是提升模型性能、稳定性与可解释性的关键步骤。合理的特征筛选不仅能减少噪音,防止过拟合,还能使模型更具可维护性,便于业务层面解释和应用。然而,面对同一份数据集,不同的特征选择方法却经常给出截然不同的结果,让模型开发者陷入困惑:究竟该相信哪一种结果?为何这些方法之间的分歧如此显著?为了破解这一谜题,本文深入分析了五种主流特征选择方法,结合真实的信用风险数据集进行对比,剖析为何特征选择方法难以达成一致背后的本质原因。首先了解所用数据场景与预处理方式是分析的基础。实验所用的信用风险数据来自Kaggle,目标变量为客户是否具有风险(风险与非风险二分类)。其特征集合包括客户的行为数据,如账户余额、逾期次数及还款模式,同时涵盖人口统计学信息。
数据本身具有现实复杂性,诸如多个高度相关的特征(例如最高余额与最新余额相关系数高达约0.75),包含大量类别变量及偏斜分布的数值变量。为了保证客观公平,五种特征选择方法均基于相同的数据拆分与预处理步骤,确保结果对比合理。第一种是基于树模型的特征重要性排名。传统决策树通过挑选能最大减少不纯度(类别混合程度)的特征进行分裂,累计分裂贡献形成特征重要性评分。这种方法偏好那些能够提供干净切分的特征,尤其是类别数目多或连续数值型特征因有更多分割点往往获得更高分数。高度相关的特征中,树模型倾向选出其中一项作为"冠军",掩盖了其他同相关特征的重要性。
实验证明,诸如fea_2、fea_4等类别型变量因能提供明显的分割点而名列前茅,而高度相关的highest_balance击败了new_balance,正体现了树模型"相关性轮盘赌"的偏好。树模型强调数据中的"切分利器",但这不意味着这些特征一定持续驱动预测。接下来分析SHAP值。SHAP源自合作博弈论的Shapley值,目标是公平衡量每个特征对单个预测的贡献。通过考虑所有加入特征的可能顺序,计算每个特征对预测带来的期望边际贡献,再进行整体样本均值化,得到全局的特征重要性。SHAP的优点在于它对相关特征的处理较为公平,能避免树模型那种"只选一方"的任意偏好,而且能揭示那些虽不在主要分割却持续微调预测的"沉默推手"。
实验证明,SHAP与树模型一致认可了fea_2和fea_4的关键地位,但也让fea_1和new_balance等被树模型少用的特征显露身影,反映它们稳健地影响着许多客户的预测结果。而最高余额和prod_code虽然在树模型中排名靠前,SHAP却表现较弱,暗示它们更像切分利器而非持续性驱动力。递归特征消除法(RFE)则体现了另一种视角。RFE从全量特征出发,训练模型后逐步删除贡献最小的特征,重复执行直至达到预设特征数量。通过结合嵌套交叉验证,RFE可动态评估子集对预测性能的影响。其价值在于考虑特征组合效应,即使某特征单独作用有限,但在与其他特征交互下能提升模型表现。
实验证明,RFE最终保留了一些SHAP和树模型均不突出但组合有意义的特征,比如多个逾期计数变量和fea_5,体现了特征间互补力量。Boruta方法通过构建随机森林和"影子特征"(对原特征值进行随机打乱生成),以统计显著性判定特征是否优于纯随机噪声。其保守性较强,偏向只保留显著稳健的核心特征,往往剔除边缘或依赖于交互作用的辅助变量。在实验中,Boruta确认了一组较为紧凑的核心特征集,几乎是适用于多种情况的"坚实内核"。最后,置换重要性方法提供了最切实的实测视角。通过打乱单个特征的值,观察模型性能(如准确率)下降的幅度,判断其对模型贡献大小。
此方法能剔除对预测无效甚至负面影响的变量,在应对相关特征时存在一定缺陷,因为相关特征间替代性高,单独打乱不易体现其真实作用。实验发现fea_2依然是最重要的特征,fea_1也提供了实质性贡献,而fea_3和fea_0则被判定为有害特征,剔除后模型表现提升。将五种方法放在一起对比,可见虽然存在核心特征的共识,如fea_4、fea_8、fea_10和fea_11等"全天候驱动力",但在部分特征的评价上存在显著分歧。尤其是对高度相关的highest_balance与new_balance,树模型明显偏好前者作为早期分裂点,SHAP更看重后者的持续贡献,而置换重要性方法显示特征间替代性降低了各自的重要评分。综合来看,如果目的是解释性和生产环境的稳定性,new_balance或许是更安全的选择。对于feat_1和pay_normal等"沉默推手",SHAP和置换重要性能体现其稳定影响,而树模型因其依赖切分机制,常常忽略它们。
RFE则强调特征间的协同作用,阐释交互效应的重要性,这对监管合规和实际业务具有特殊意义。另一方面,置换重要性能够明显指出负面贡献特征,提示模型开发者剔除潜在噪声和过拟合源,这一特性在其他方法中较为隐晦。综上,不同的特征选择方法本质上是从不同的统计学和算法视角观察数据。它们的分歧反映了各算法机制、假设和偏好的差异,而非简单的矛盾或误差。因此,将特征选择视为一场多方对话,而非单一裁判的判决,有助于构建更全面、稳健的特征体系。实践中,可采用"以宽带开路,逐步精炼"的策略:先用树模型快速筛选候选特征,再借助SHAP揭示关键影响路径,利用Boruta锁定核心稳健变量,结合RFE评估交互作用,最终用置换重要性验证最终集对模型性能的实质贡献,同时关注特征稳定性和业务解释性。
通过多角度融合,不仅能获得相对稳定的"特征骨干",还可深入理解模型内部逻辑和特征作用机制,为模型解释、调优和风险控制提供坚实基础。特征选择并非简单的"删繁就简",而是机器学习建模中的灵魂时刻。它折射出模型对数据的认知方式,展现数据与算法间的复杂互动。借助不同方法的视角,我们可以更加坦然面对特征选择过程中的不一致,拥抱这些差异所蕴含的宝贵信息。正如本文所示,五种侧重点各异的筛选技术联袂演绎,构成了对信用风险数据深刻而多维的理解,赋予模型更强的解释力和鲁棒性。只有善用这些镜头,方能让模型真正立于不败之地,赢得业务部门与监管机构的信赖。
。