在现代互联网业务的高速发展中,监控系统作为保障服务稳定运行的关键组件,面临着指标数据量呈爆炸式增长的挑战。尤其是在大规模分布式系统环境下,每秒产生的指标数量庞大,给指标存储、查询及分析带来了巨大的压力。Flipkart在其API Gateway系统中,成功应对了超过8000万个时间序列指标的采集与管理难题,这背后离不开Prometheus的巧妙应用和系统架构的合理设计。本文将深入剖析如何利用Prometheus实现大规模指标的平滑扩展,帮助你理解应对海量指标采集的核心方法及其在实际生产环境中的落地经验。 Flipkart面临的挑战始于其API Gateway层。大约有2000个实例的网关应用,每个实例产生近40000个不同的指标指标总量迅速攀升至超过8000万个时间序列数据点。
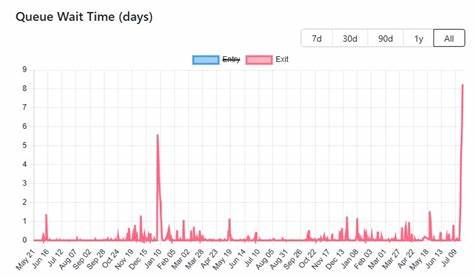
指标涵盖了请求速率、各种错误率、定制的JMX指标以及细粒度的延迟统计量(如p95、p99延迟)。在使用传统的StatsD方案时,虽然初期能满足基本需求,但面对超过3小时以上的历史数据查询,系统表现开始变差。数据存储逐渐成为瓶颈,导致查询性能急剧下降,难以支撑长期的运维分析和趋势洞察。 在此背景下,Prometheus作为一种开源的、功能强大的监控和报警系统被引入。Prometheus采用拉模式(pull-based)采集指标,不同于StatsD推送模式,有效降低了数据传输的复杂度和系统耦合度。它内置强大的PromQL查询语言,支持多维度复杂的指标聚合和统计,使得长期指标分析变得更加高效和灵活。
此外,Prometheus良好的生态体系兼容多种云平台和容器编排环境,如Kubernetes、AWS、Azure等,极大地扩展了指标采集的范围和深度。 在Flipkart的实践中,采用了Prometheus的联邦架构(federation),通过层级聚合方式实现了监控系统的横向扩展。具体来说,每个Prometheus服务器负责采集指定的指标集合,并在本地对指标进行预聚合处理,例如去除实例标签,聚合计算请求数量、错误率以及延迟分布等。经过聚合后的指标被暴露在一个新的端点供上游的Prometheus联邦服务器采集。联邦服务器进一步对跨集群或跨区域的指标进行汇总,写入远程存储,供后续的可视化面板展示和告警规则计算。 这种层级聚合不仅显著降低了指标的基数(cardinality),还极大地节省了存储空间和查询资源。
例如,在本地集群中,原本2000个实例×40000个指标共计约8000万条时间序列,经由去除实例标签及聚合变换后,仅剩约40000条指标指标,大幅度降低了存储需求。从存储成本角度来看,传统方案每日存储需求达到4TB的量级,经过聚合优化后,存储需求下降到2GB每日至,大幅度降低了硬件投入和运维复杂度。 在选择是否启用联邦架构时,需权衡使用场景和监控需求。如果组织跨多个区域或集群且需要统一的全局视图,联邦架构能够提供高效的扩展能力。当单一Prometheus服务器触及资源极限时,联邦也能实现水平扩展。但若仅在单集群环境且对单实例指标调试需求较高时,联邦架构的复杂度反而可能带来不利影响。
在此情境下,维护单一Prometheus实例及远程存储结合的方案更为合适。 架构设计中关键的一环是标签的合理管理。Flipkart通过录制规则(recording rules)实现指标的预计算和标签降维。去除高基数的实例标签,保留服务名和集群名等稳定标签,从而保证聚合指标的准确性和可读性。在延迟指标如p95、p99的处理上,除聚合计算百分位数外,还对平均值、最大值和最小值进行统计,反映出在不同层面上的性能表现。 整体的数据流从Kubernetes的Pods(作为监控目标)通过Prometheus的Service Discovery机制动态识别,Prometheus服务定时拉取指标数据后执行规则计算和标签重写,最终写入远程存储系统实现高效的长周期数据存储。
借助Grafana等可视化工具,运维团队能够实时监控核心指标趋势,自定义丰富的告警策略,保障系统稳定运行。 实现这一系统方案需要详细的配置管理。Prometheus配置文件中合理设置全局抓取周期、超时时间,利用Relabel配置精确筛选抓取目标及指标,避免不必要的监控负担。通过remote_write接口将预聚合数据写入持久化存储,确保业务团队能够快速访问历史数据。联邦任务的配置则要求匹配特定指标,过滤细化后的结果上送,实现数据的有序汇总。 Flipkart的成功经验启示我们,面对海量指标的监控需求,单一工具或模式常常难以胜任,需要创新的架构设计和组合使用现有技术优势。
Prometheus通过其灵活的采集模式、强大的查询语言、多样的标签体系及扩展能力,为构建现代、高性能监控平台提供了坚实的基础。此外,在实际项目中合理利用聚合、标签降维及分层采集策略,能够将庞大复杂的指标数据转化为可洞察、可操作的指标信息,极大提升监控效率和运维响应速度。 未来,随着业务体系规模继续扩大,监控系统的挑战也会随之增长。Prometheus社区不断迭代和优化,包括引入Thanos和Mimir等组件,加强对长周期存储和跨区域高可用的支持,为大规模指标管理提供了更完善的解决方案。借鉴Flipkart的实战案例与架构思路,运维工程师和开发者可制定符合自身业务特点的监控规划,确保在数据量激增的环境下依然能够平稳、高效地管理和分析指标数据,推动业务稳定健康发展。 综上所述,Prometheus不仅是一款强大的监控工具,更是构建大规模分布式系统监控架构的基石。
通过联邦架构、标签优化及录制规则等关键技术手段,Flipkart成功实现了对8000万级别指标的高效管理。未来,随着技术的演进,相关方案也将不断完善,帮助更多企业解决大数据量监控的瓶颈,实现智能、高效的运维管理。 。