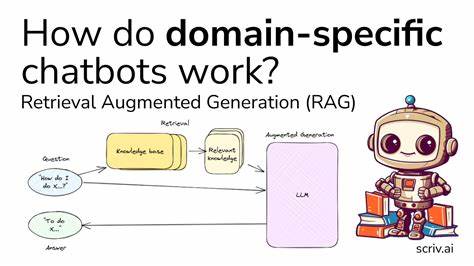
随着信息爆炸时代的到来,现代读者面对海量的阅读笔记和高密度的信息输入时,如何高效管理和灵活调用这些知识,成为提升个人生产力和学习成果的关键。Readwise 作为一款备受欢迎的阅读摘录管理工具,广泛帮助用户集中收录、分类和复习他们来自不同平台的精彩书摘笔记。然而,面对不断增长的数据量,传统的关键词搜索模式已经无法满足高效回溯与关联思考的需求,于是基于语义理解的搜索技术便应运而生。所谓语义搜索,是指搜索引擎不仅仅按关键词匹配内容,还能基于内容的深层含义进行信息检索,从而找到真正相关的知识点。这种技术突破了字面文本的束缚,让检索结果更符合用户的意图。结合本地部署的优势,用户不仅能够确保数据的安全隐私,而且无需依赖云端网络,可以实现更快的响应速度和更自由的自定义操作。
近期,一项名为“Readwise Vector DB”的开源项目,为广大读者带来了革命性的工具选择。它通过将 Readwise 库的笔记转换成向量表示,利用 PostgreSQL 扩展 pgvector 支持的向量搜索,实现了一套功能强大且自托管的语义搜索系统。这套系统支持多种部署方式,包括本地 Docker 容器环境和云端 Supabase 数据库,对不同使用场景进行了优化。其核心技术架构结合了 FastAPI 服务器、OpenAI 的语言模型以及高效的数据库索引,能够做到对文本内容的语义进行深度理解和快速匹配。用户只需导出 Readwise 中的摘录数据,通过预设的同步工具进行数据更新,即可拥有一套完全属于自己的智能搜索库。相比传统的全文检索,向量搜索能够根据查询语句与你的笔记内容之间的语义距离,评估相关性,显著提升搜索的准确度和体验。
它不仅支持基于关键词的简单过滤,还能结合标签、时间戳、来源等多维度条件,实现更精细的知识筛选。值得一提的是,Readwise Vector DB 还内置了实时流式搜索功能,借助服务器发送事件(SSE)技术,允许用户边输入边动态获得排布优化的搜索结果,极大提升交互的流畅度。这种设计充分利用了现代服务架构的优势,适配无状态函数计算的无服务器平台,如 Vercel,方便开发者快速部署和扩展。对于技术门槛较低的普通用户,在云端平台(如 Supabase)一键部署成为可能,解除了传统数据库搭建的烦恼。通过简单的命令行操作,配合环境变量配置,即可保证数据的定期同步、备份及版本管理。作为一款优质的开源软件,它还支持丰富的开发、调试和贡献工具,社区活跃,维护良好,使得项目始终保持最新技术兼容性与性能优化。
读者可以根据自身需求,选择全本地化环境以保护隐私,或采用云端方案实现全球访问和自动扩展。对于内容创作者、研究人员以及知识管理爱好者来说,结合 Readwise 的文摘库打造一个语义智能搜索平台,无疑是一场效率的飞跃。用户不仅能够更快找到关键内容,还能轻松发现不同摘录之间的隐藏联系,实现知识的深度整合。通过这种方式,碎片化的阅读记录不再是零散的信息点,而是逐渐形成体系化的知识网络,助力学习和创新。技术上,Readwise Vector DB 利用了 PostgreSQL 强大的扩展能力,结合 pgvector 插件提供的向量相似度搜索,同时结合 Alembic 管理数据库模式,保证数据迁移的兼容和可维护。Python Poery 管理依赖、FastAPI 构建高性能异步 API,配合 Docker 容器实现环境隔离和便捷部署,体现了现代云原生技术的最佳实践。
借助 OpenAI 提供的文本嵌入接口,系统将输入文本映射为向量,将语义维度纳入搜索逻辑,极大丰富了检索的深度。对于未来展望,随着大模型技术和向量数据库的快速发展,类似平台将更普及,个性化知识库管理成为常态。结合人工智能预训练模型,用户可以实现自动摘要、智能标签生成、内容推荐等更丰富功能,进一步打通从阅读到知识生产的全链条。总之,基于本地语义搜索技术强化的 Readwise 读书摘录库不仅显著提升了信息管理效率,也开启了智能知识服务的新纪元。无论是专业学者、行业研究者,还是普通的读书爱好者,都能通过这套系统获得更便捷、更精准、更安全的智慧阅读体验。伴随技术和应用的不断迭代,未来的数字阅读和知识管理,将更加智能化、个性化,真正实现知识的无限价值释放。
。