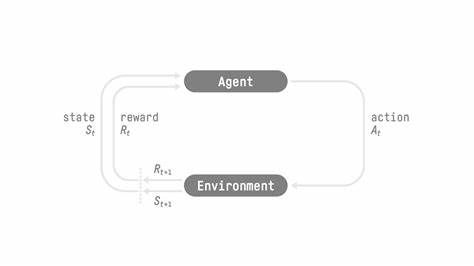
随着人工智能领域的迅猛发展,智能代理在自动化任务处理、自然语言理解、决策优化等方面的应用越来越广泛。强化学习作为训练智能代理的重要方法,因其能够让模型通过奖励机制不断优化表现而备受关注。然而,现有强化学习框架在多轮任务支持、计算资源利用率以及与既有代理代码库的兼容性方面存在诸多不足。近期,一款名为ART(Agent Reinforcement Trainer)的开源强化学习框架横空出世,凭借其设计理念与技术优势,为智能代理训练带来了全新可能。 ART框架由OpenPipe团队历时数月开发,目标是打造一个灵活、高效且易于集成的强化学习训练平台。与传统框架相比,ART不仅支持复杂的多轮交互流程,还极大提升了GPU资源的利用效率。
此外,其兼容OpenAI API标准,能够作为现有文本生成与对话系统的无缝替代方案,方便开发者快速部署和迭代训练。 在细节设计上,ART摒弃了传统训练体系中的硬性回调函数和流程限制,改为提供一个完全开放且可定制的训练管线。通过模拟智能代理与环境交互的多个步骤,框架允许模型调用工具、处理响应并基于反馈继续决策,这种多步执行支持填补了市面上多数RL框架的空白。此特性尤其适用于需要连续操作和策略调整的复杂任务,如信息检索、对话管理等场景。 GPU利用率方面,ART采取了优化的异步计算与流水线策略,确保训练过程中Rollout阶段和模型更新阶段的GPU资源均被充分使用。传统框架通常因阶段切换停顿导致资源浪费,甚至需要多卡H100 GPU才能完成小规模7B参数模型训练。
而ART通过智能调度极大缩减了硬件门槛,使中小型团队也能高效开展强化学习项目。 与此同时,ART在API设计层面紧跟行业标准。开发者可以通过兼容OpenAI聊天补全接口的API,轻松与现有应用集成,无需重新设计交互逻辑。此举不仅降低了学习成本,也促进了生态系统内不同工具和框架的互操作性,推动智能代理研发更快落地。 OpenPipe团队在实战中率先用ART框架训练了一款高效的邮件搜索智能代理。该代理通过强化学习逐步掌握关键词选择策略,大幅提升了相关邮件的检索速度和准确率。
此前,团队依赖传统方法无法有效设计出此类策略,强化学习的应用则使模型自主探索并改进行为。相关详细介绍和演示案例已经公开,为有兴趣的研究者和开发者提供了宝贵参考。 ART不仅适合用于构建面向业务的智能助手,还具备广泛的研究和实验价值。其灵活的奖励机制设计让用户能够为不同任务定义专属优化目标,无论是代码生成、对话调控还是复杂规划,都可以利用强化学习的优势逐步完善模型表现。随着模型能力提升和训练成本降低,开源社区有望围绕ART展开更多创新,推动智能代理技术走向新高。 面对快速变化的人工智能发展格局,拥有一个开放、易用且高效的强化学习训练工具显得尤为重要。
ART以其实用的设计理念和成熟的技术实现,完美契合此需求。它不仅帮助团队提升训练效率和模型质量,还简化了开发流程,缩短了产品落地周期。 未来,ART计划进一步丰富功能与文档支持,完善API的稳定性和可扩展性。同时,团队鼓励更多开发者参与社区建设,共同推动框架迭代与优化。随着更多成功应用案例的涌现,ART有望成为强化学习领域的重要组成部分,助力AI技术服务于更多实际场景。 总的来说,ART是强化学习领域的一颗新星,提供了面向复杂多阶段任务训练的强大工具,解决了传统框架的多项痛点。
它结合高效资源利用和开放灵活的接口设计,为开发者打造出一个训练智能代理的理想平台。无论是在学术研究还是工业应用中,ART都展现出极大潜力,其未来发展值得期待。智能代理训练的新时代,正因ART而启航。