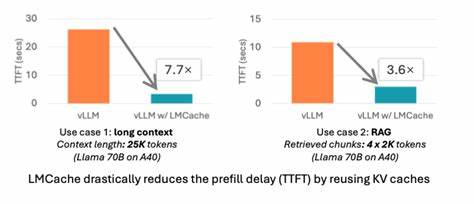
近年来,随着大语言模型在自然语言处理、对话系统、知识问答和生成任务中的广泛应用,模型推理效率问题日益突出。大语言模型具有庞大的参数规模和长上下文依赖,推理过程中的计算资源消耗极大,尤其是在多轮对话或重复查询的场景中,冗余计算带来的资源浪费不容忽视。为解决这一痛点,LMCache应运而生,作为一种专门用于LLM推理加速的缓存方案,深度整合了存储和计算流程,实现了高效的KV缓存复用,从而显著缩短了首次响应时间(TTFT)并提升整体吞吐量。LMCache的设计理念源自Redis等高性能缓存系统,但针对大语言模型的结构特点进行了优化调整。传统的缓存系统主要关注键值对的快速存取,而LMCache则针对LLM推理中的键值对(Key-Value Cache)进行了专业化处理,KV缓存用于存储Transformer模型推理时的中间状态,复用这些缓存可以避免重复计算,从而极大地节约GPU周期。该系统通过多层存储架构,将KV缓存分布于GPU内存、CPU DRAM和本地磁盘等多个位置,确保缓存可以根据访问频率和存储容量进行灵活调度。
这种多级缓存策略既保障了高访问速度,又兼顾了大规模缓存数据的存储需求。LMCache特别强调非前缀KV缓存的支持,这意味着它不仅能复用文本开头部分的缓存,还能针对句子或段落中任意可复用的文本片段缓存中间计算结果,这极大扩展了缓存适用范围,适合多轮问答、检索增强生成(RAG)等复杂应用场景。与vLLM的深度集成是LMCache的一大亮点,vLLM作为高性能开源LLM推理框架,与LMCache组合后能实现3-10倍的延迟减少及GPU计算资源节省。LMCache提供了高效的CPU侧KV缓存卸载能力,支持分布式预填充和点对点的KV缓存共享,提升了缓存命中率和系统的整体吞吐能力。安装和使用方面,LMCache支持Linux NVIDIA GPU平台,通过简单的pip命令即可快速部署,兼容性强。官方文档和示例演示涵盖了多个应用场景,方便开发者迅速上手。
LMCache的开源生态活跃,社区贡献者众多,项目拥有超过五千颗星标和六百余次分叉,定期举办双周社区会议,分享经验,推动技术进步。对于企业用户,则提供了基于vLLM的生产级部署方案,以及对主流推理服务平台如llm-d和KServe的官方支持,确保其在实际业务中稳定运行。从技术角度看,LMCache的核心优势在于其KV缓存压缩和流式传输技术,这缩减了缓存存储的空间需求,同时提升了缓存加载和更新的效率。相关论文《Cachegen》和《Do Large Language Models Need a Content Delivery Network?》对这些技术细节进行了深入剖析。实验证明,LMCache在多轮对话和信息检索辅助生成任务中,能够大幅度降低模型响应时间,并减少GPU资源消耗,表现优于传统缓存策略。在实际应用中,LMCache不仅帮助企业节省了昂贵的计算成本,还优化了用户体验,使得基于LLM的智能产品能够提供更加流畅和即时的交互响应。
展望未来,随着大语言模型不断发展,应用场景日趋多样化,对缓存系统的性能和智能化提出了更高要求。LMCache将在持续优化KV缓存管理和支持更多硬件平台方面发力,推动LLM服务走向更广泛的规模化和高效部署。总的来说,LMCache作为一种专为LLM推理设计的Redis风格KV缓存解决方案,凭借其创新的缓存复用机制、多层存储架构及与领先推理框架的紧密集成,赋能了大语言模型服务的技术进步。它不仅降低了计算成本,提高了响应速度,也推动了人工智能应用的实际落地和商业化,为开发者和企业用户带来了切实的价值提升。在如今大语言模型竞争日益激烈的时代,LMCache代表了缓存技术的前沿趋势,值得所有关注LLM性能优化的研究者和从业者高度重视和积极尝试。随着开源社区的持续壮大与技术不断迭代,将有更多创新功能和优化方案陆续释出,LMCache的生态体系和技术影响力势必进一步提升,真正实现“为大语言模型量身打造的高性能缓存”这一目标。
。