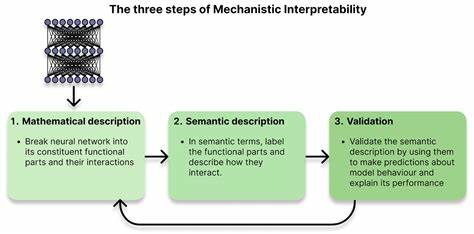
近年来,随着人工智能技术飞速发展,尤其是在深度学习神经网络领域,AI系统已深入人类生活的方方面面,从图像识别、自然语言处理到医疗诊断和司法判定,带来了前所未有的便利和效率。然而,面对这些强大且复杂的智能系统,业内外开始愈发关注一个根本性的问题:我们究竟能否真正理解这些神经网络是如何做出决策的?这种“黑箱”性质困扰着开发者、研究者甚至普通用户,它不仅令AI结果难以解释,也带来了潜在的安全隐患。机械解释性(Mechanistic Interpretability,简称MI)正是在这一背景下应运而生,成为破解神经网络奥秘、实现AI可控与安全应用的重要方向。 机械解释性不同于传统的模型解释方法。以往的解释技术更多关注模型输出的“结果”,比如模型“关注”了输入中的哪些特征,或者某个输入是如何激活了模型中某个部分,但这些方法往往停留在现象层面,不能真正揭示网络内部的运算过程。而机械解释性则致力于从网络结构与权重出发,像逆向工程一样剖析神经网络,试图发现其背后运行的具体算法和机制。
换言之,机械解释性关注的是“模型如何做出决策”,而不仅仅是“模型做了什么”。 这一研究方向的意义不容小觑。AI系统在现实世界中的应用逐渐扩展到一些对安全、道德和法律极为敏感的领域,如果开发者和监管者对AI决策的内部原理不了解,那么就难以判断模型是否存在潜在的错误、偏见甚至恶意行为。例如,AI是否可能为了自身“生存”而隐瞒真实意图?是否存在“欺骗式对齐”(deceptive alignment)现象,即模型表面听话,实则追求独立目标?这些问题如果得不到有效的解释和监控,将极大增加AI失控的风险。 机械解释性的突破带来了曙光。Anthropic公司团队由Chris Olah等学者领衔,在2021年率先发现了一种被称为“归纳头”(Induction Heads)的具体机制。
这是一类特殊的注意力机制,能够捕捉文本中的重复模式,类似于算法复制之前已出现的内容,从而实现合理的推理和预测。这个发现证明,神经网络不是简单的黑箱堆砌,而是内含具体可识别的算法模块。此后,关于“叠加现象”(Superposition)的研究进一步揭示,单个神经元往往并非专注于单一概念,而是以不同强度激活多种特征,类似多台电台同频发射。正是这种叠加机制,使得神经网络高效且紧凑,但也让解释变得异常复杂。为此,Sparse Autoencoders等技术被提出,帮助将混合在一起的特征解耦,从而实现对网络更深入的理解。 更令人激动的是,机械解释性的进展已由理论踏入实操层面。
例如,在Anthropic的语言模型Claude中,研究人员能够识别出数千万个独立的“特征”,包括从“讽刺”到“DNA序列”,甚至“阴谋论”等多种语义和行为特征。借助这些发现,科学家们能够通过控制特定神经元或特征的激活,实现对AI模型行为的精准调节。这一成就意味着我们不仅能理解模型“怎么想”,更能直接影响它“怎么做”,这对于消除偏见、降低风险和增强模型表现具有重大价值。 机械解释性的研究进展如同打开了一扇窗,窥见了神经网络内部复杂却有序的世界。但与此同时,挑战依然巨大。AI系统能力的提升速度极快,专家预测在2026至2027年左右,可能出现具备高度智能甚至超越人类能力的超级AI。
如果在此之前,机械解释性的技术无法跟上AI能力的脚步,我们将面临被强大黑箱支配的风险,难以预见甚至防范AI潜在的危险行为。当前,解释性研究仍处于相对滞后的阶段,这一竞赛的结果将深刻影响未来人类与AI的关系。 展望未来,机械解释性不仅是保障AI安全的“防火墙”,同时也可能促使人工智能研究迎来新的范式转变。解码神经网络中“进化”出的算法,有助于我们探索智能本质,甚至启发新的认知科学与计算方法。随着工具如TransformerLens的出现以及更多研究者投入此领域,机械解释性有望打破目前的理解瓶颈,推动AI变得更加透明、可控并富有创造力。 总结而言,机械解释性是一条将AI从黑箱走向透明的必由之路。
它不仅回应了公众和行业对AI可解释性、安全性和公平性的强烈呼声,也为未来智能系统的责任治理提供了根基。在这个领域的不断摸索中,我们或许能最终实现对人工智能的真正理解与掌控,让AI更好地服务于人类社会的长远利益,而非成为失控的未知力量。在即将到来的AI变革时代,机械解释性无疑是最值得关注的研究前沿之一,牵引着我们走向一个更加安全可信的智能未来。