近年来,随着大规模预训练语言模型的发展,问答系统得到了飞速提升。然而,尽管在短文本问答中表现优异,长文本问答系统面对海量信息和复杂推理仍面临诸多挑战。长文本问答系统指的是能够从书籍、长篇技术文档、多篇关联文献中提取并整合信息,为用户提供准确、全面回答的人工智能系统。要想真正发挥其作用,就必须建立科学、精准的评估体系。评估不仅是性能衡量的工具,更是驱动模型优化的关键动力。本文将从评估维度、数据集构建、人工标注与模型辅助评估、现有代表性基准测试等方面,系统阐述长文本问答系统的评估方法与难点。
长文本问答系统不同于短文本问答,主要在处理的文本长度和信息复杂程度上表现出显著区别。长文本往往包含大量无关信息,这就使得信息检索和模型注意力机制都面临“信息过载”问题。模型如何有效聚焦于与问题相关的片段,避免被大量琐碎细节干扰,是评估重点之一。此外,长文本中有价值的线索可能出现在文本开头、中间甚至末尾,模型如何应对“中间信息遗失”问题,也是设计和评估体系时必须考虑的因素。 多跳推理是长文本问答的另一大难点。用户提出的问题通常涉及分散在文本不同位置的多条信息,模型需要将这些信息综合关联,生成符合语境要求的答案。
评估体系必须考察模型在跨段、跨文档信息整合方面的能力。与此同时,长文本的规模放大了“幻觉”风险,即模型基于错误或检索不到的信息生成貌似合理却不准确的回答,这对评估的准确性提出更高要求。 评估维度方面,忠实性(Faithfulness)和帮助性(Helpfulness)被认为是衡量问答系统表现的两条核心维度。忠实性强调回答必须严格依赖于源文本,避免引入外部知识或虚构内容。其重要性在于一些领域如法律合同、医疗说明等对信息来源的准确依赖性极高。忠实的回答还应具备辨识信息缺失的能力,当文档中无法找到答案时,模型应合理拒答而非凭空编造。
与忠实性相辅相成的是帮助性,它关注回答的相关性、完整性和简洁性。帮助性好的回答不仅忠实,还能紧扣用户问题,提供所需信息的充分细节,但又避免冗长繁杂,难以理解。实现忠实与帮助性的平衡,是评估及系统设计的艺术所在。 传统基于词汇或句子重叠的评估指标如BLEU、ROUGE等已被证明并不适合长文本问答任务。这些指标容易误判答案的质量,尤其当答案与参考答案在用词或长度上存在差异时。模型基于语义和逻辑的判别显得尤为重要。
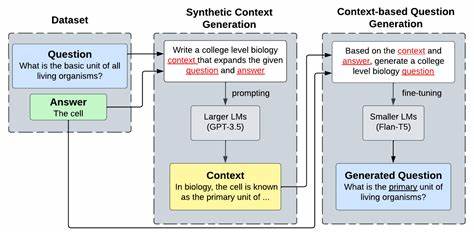
因此,近年来人们更多地采用大语言模型作为“评判者”,通过预设评价标准对答案进行综合打分,表现出更高的精确度和与人工评判的一致性。 构建高质量的评估数据集是开展长文本问答评测工作的基础。生成符合实际应用场景的问题是关键环节。人工设计虽精确,但效率低下且难以大规模操作。利用大语言模型辅助生成问题,再由人类专家筛选与修订,是当前较为高效的做法。设计问题时要避免简单事实回溯式问题,更多关注叙事理解、多跳推理和无信息可答的问题,从而全面考察系统能力。
数据集设计应确保问题类型多样,包括事实提取、定义解释、内容总结、推断推理以及无答案判断等。更重要的是,问题需均匀覆盖文档的不同部分,挑战模型在信息定位及综合利用上的能力。部分先进数据集如NarrativeQA、NovelQA就采用了由摘要生成问题的方法,减少模型利用表面文本匹配的机会,提高了测试的严谨性和深度。 评估过程中的人工标注依然占据重要地位。标注人员根据预设定义,评判答案的忠实性及帮助性,或通过对比判断两答案谁更为实用。为保证标注质量,需制定清晰的指导手册,设计资格测试并持续优化标注流程,同时使用多标注者交叉校验指标如Cohen’s Kappa来衡量一致性。
专业领域则可引入具备相关背景知识的专家以提升评估的权威性和准确度。 不过感受到人工标注的昂贵成本和时间消耗,研究者逐渐转向利用如GPT-4等大语言模型作为自动评估器,按照人工标注标准和原则对答案进行打分和判断。此类“模型评估器”通过调优和校准,能够在一定程度上复制人类的评判方式,同时大幅提高评估的规模和效率。从多个公开研究和基准也证明了其在忠实性和帮助性判断上的显著优势。 遗憾的是,不同类型的问题以及长文本特殊的上下文结构,仍然对模型评估器提出挑战。例如,多跳推理捕捉效果、跨文档信息融合质量,模型仍有失准现象。
此外,模型能否正确拒答无信息问题,防止幻觉产生,也是评估器设计中的重要关注点。 目前已有多个深具代表性的长文本问答基准被广泛应用,这些基准不仅提供了统一试验平台,也揭示了现阶段模型的不足和研究方向。NarrativeQA通过来自小说与电影剧本的大量事件整合问题,考察模型的整体叙事能力。NovelQA更新升级,将难度扩展至二十万以上的文本级别,强化了多章节信息整合。QASPER聚焦学术论文中的信息检索与综合,特别注重支持证据的定位和准确性。 L-Eval通过收集从数千到二十万字不等的大规模文本,融合闭合式和开放式问答任务,使用人类与大语言模型混合评估,为长文本理解力提供了更大视野。
HELMET则针对评估方法的规范化和长上下文模型的适应性,提供了丰富任务类型和严谨的测评标准。 Loong关注真实多文档场景,模拟了金融、法律及学术环境下跨文档推理和信息整合,体现现实应用中长文本问答系统的复杂性。 这些基准的差异化设计充分反映了长文本问答领域的多样化需求:单文档与多文档、叙事文本与技术文献、基础事实检索与复杂推理一应俱全。它们共同推动了模型技术向更高理解力和泛化性迈进。 除了数据和评估体系,长文本问答的实际应用还需要关注问题本身的设计。问题应覆盖不同难度、多样主题及推理类别,兼顾可答性与挑战性。
对模型输出的要求也不能仅停留在“答案正确”,而是要评估其答案的可用性、贴合性和表达逻辑。只有这样,基于长文本的问答系统才能满足用户尤其是专业用户的真实需求,比如法律顾问、医生和学者。 综合来看,评估长文本问答系统是一项技术与策略并重的工程。忠实性和帮助性的度量、问答数据的多样化设计、人工标注与自动评估器的有效结合,以及严谨的基准测试,共同构建了科学评测的基石。未来,随着上下文处理能力的提升和对模型解释能力的强调,评估体系也会不断完善,更好地促进长文本问答技术应用于实际场景。 对研究人员和从业者而言,理解并掌握这些评估原则与方法,既是推动问答系统发展的必要条件,也助力设计出更加智能和高效的长文本信息服务。
随着相关技术和资源的丰富,长文本问答系统将能更精准地满足不断增长的知识获取需求,开创知识服务的新篇章。