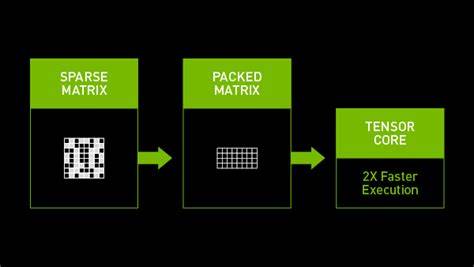
随着人工智能技术的不断发展,模型的规模和复杂度迅速增加,带来了巨大的计算需求和能耗挑战。针对这一问题,优化AI推理速度和效率成为行业的核心目标。近期,NVIDIA推出的2:4半结构化稀疏性技术受到了广泛关注,这项创新技术能够在硬件层面实现AI推理加速,提升效率高达27%,为人工智能应用带来了革命性影响。 2:4稀疏性是一种结合半结构化约束的稀疏模式,它在神经网络权重矩阵的存储和计算过程中引入规律性。具体表现为每组4个权重值中有2个被置为零,实现了稀疏化但又不会过度随机分布。这种结构化特点极大地便利了硬件加速和计算优化。
相比无结构稀疏性,2:4半结构化稀疏性可以更好地被现代GPU架构识别和利用,尤其是NVIDIA的Ampere架构在设计时就针对这种稀疏模型进行了优化。 在NVIDIA的最新硬件中,半结构化稀疏性的支持体现在Tensor Core的设计上。通过专门的计数和计算单元,Tensor Core能有效跳过为零的权重计算,节省大量计算资源和能耗。这种跳过零权重的能力,使得计算效率得到了质的提升,同时在保持模型精度的前提下,实现了更快的推理速度。 实际应用中,2:4稀疏性技术不仅加速了深度神经网络的前向推理过程,还极大地优化了模型的存储需求。由于一半的权重为零,模型的参数量大幅减少,训练和部署时的数据传输开销也同步降低。
这对边缘设备和资源有限的环境尤为关键,有助于实现更广泛的AI普及。 除了硬件加速的优势,2:4半结构化稀疏性还对模型训练提出了新的挑战和机遇。为了保证稀疏性模式下模型的准确性,研究人员设计了专用的训练算法和剪枝策略,使模型能够在稀疏约束下更有效地学习和泛化。NVIDIA及其合作伙伴相继发布了支持稀疏训练的深度学习框架和库,极大地方便了开发者利用这种新兴技术。 随着越来越多的AI应用开始采用更大规模的模型,计算效率的提升变得尤为重要。2:4半结构化稀疏性技术在无需牺牲精度的前提下,实现了计算资源的最大化利用,是迈向高效AI计算的关键一步。
无论是在自然语言处理、计算机视觉还是推荐系统等领域,这项技术都展现出了广泛的适用性和强大的性能提升潜力。 数字化时代对实时响应和低延迟的需求持续增长,2:4半结构化稀疏性能够显著缩短推理时间,为自动驾驶、智能助理、实时翻译等场景提供更流畅的用户体验。同时,节省的计算资源也意味着减少了碳排放,对绿色计算和可持续发展目标起到推动作用。 未来,随着技术的不断成熟和硬件生态的完善,2:4半结构化稀疏性有望与其它优化技术如量化、剪枝和算法加速深度融合,带来更高的AI计算效率和更强的智能能力。NVIDIA作为领先的图形和AI计算厂商,仍将致力于推动稀疏性技术的创新与普及,助力业界构建更具竞争力的智能系统。 总结来看,2:4半结构化稀疏性技术是当前提升AI推理速度和效率的关键技术之一,借助NVIDIA硬件的强大支持,实现了27%的显著加速效果。
这不仅优化了计算资源利用,也推动了AI在多领域的广泛应用。未来,随着更多研究和实践的深入,稀疏性将持续成为智能计算发展的重要方向,赢得更广泛的关注和重视。 。