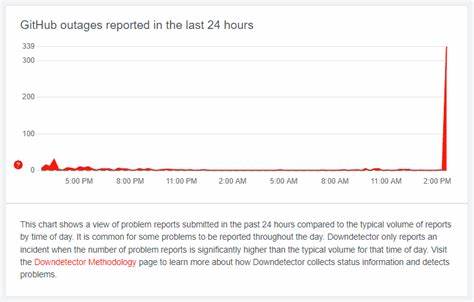
作为全球领先的代码托管平台,GitHub承载了数百万开发者和团队的项目协作与代码管理,一旦其服务出现中断,必然在全球范围内引发广泛关注与影响。近期,GitHub短暂的服务中断事件再次提醒我们,尽管技术日益完善,任何互联网服务都有可能面临不可预见的问题。本文将深入解析GitHub中断事件的具体表现、潜在成因及其对开发者社区和整个软件开发生态的深刻影响,并提供建设性的应对建议,帮助开发者更好地规划代码管理和团队协作策略。 GitHub作为全球最大开源和私有代码托管平台,集成了丰富的功能模块,包括代码版本控制、问题追踪、持续集成及多方协作等。其稳定性对全球软件开发流程的重要性不言而喻。然而,尽管有强大的基础设施和应急机制,GitHub依然难免遭遇短暂的中断。
此次事件中,用户普遍反映无法访问主页面或提交代码,部分自动化任务挂起,团队协作陷入停滞,影响了工作进度。服务于庞大用户群体的GitHub,其中断波及范围极广,相关讨论迅速在技术社区和社交媒体发酵,反映出开发者对平台依赖程度之深。 导致GitHub服务中断的原因多样,可能涉及硬件故障、网络异常、数据中心问题或软件更新失误等。尽管官方未详细公布具体故障原因,但从以往经验来看,数据中心网络拥堵或外部攻击尝试不排除是触发因素。此外,全球网络环境的复杂性使得即使单点故障也可能迅速扩散,造成全面中断。GitHub的技术团队紧急介入排查问题,通过恢复和优化系统配置,保证服务尽快恢复稳定运行,展现了强大的危机处理能力。
此次事件暴露出即使是顶尖互联网服务平台也不可避免存在潜在风险,提醒开发者在依赖单一云端平台时应有风险意识。为保障开发项目的连续性和数据安全,采用多样化的备份策略尤为关键。除了定期备份和本地镜像之外,灵活利用其他代码托管平台或自建版本控制系统,能够降低突发事件带来的影响。并且,开发团队应当设计合理的协作流程,避免完全依赖一处线上服务,确保在紧急情况下依旧能够进行必要的代码管理和项目推进。 此次GitHub中断事件也重新激发行业对云服务供应商稳定性和服务等级协议(SLA)的讨论。开发者和企业用户越来越关注平台的故障透明度、恢复时间及补偿机制,期望云服务商能提供更加完善的风险保障和快速响应能力。
未来,平台方需要进一步提升技术架构的冗余性和故障预警能力,通过智能监控和自动化修复机制,最大程度降低中断发生频率与持续时间。与此同时,加强与社区沟通,及时公开故障信息和恢复进展,也是赢得用户信任的重要因素。 从更广泛的软件生态角度来看,GitHub的稳定运行不仅关乎单一平台,更是整个开源社区活力和创新动力的支柱。全球无数开源项目依托GitHub开展,服务中断意味着开发者无法访问关键资源,社区协作受阻,软件迭代节奏放缓。这种影响在企业级开发环境中尤为显著,可能导致交付延迟和运营风险,进一步凸显平台稳定性的重要性。 开发者自身也需要借鉴本次事件中的教训,提升应对突发状况的能力。
完善代码仓库本地同步习惯,发展跨平台工作流程,增强自动化构建和测试能力,使工作尽可能不依赖单一服务环境。通过主动学习和工具多样化,减少对任一平台的深度绑定,有效应对未来潜在的服务中断风险。 综上所述,GitHub的服务中断虽然时间较短,但其带来的警示深远且及时。作为全球最大代码托管中心,GitHub未来必须持续加强系统弹性和安全运营能力,提升用户体验和信任感。开发者社区亦需强化风险防范意识和灵活应变能力,打造更健壮的协作生态和开发环境。只有平台和用户双向努力,才能共同推动软件产业稳健前行,应对数字化转型中存在的不确定性,实现生态共赢与长远发展。
。