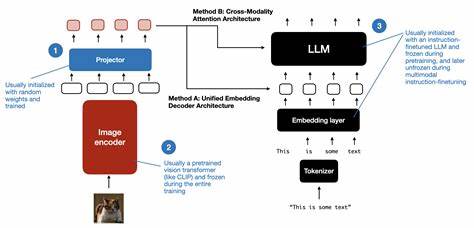
随着人工智能技术的迅猛发展,特别是大型语言模型(LLM)的出现,企业在发票处理领域迎来了创新的自动化机遇。发票处理历来是企业财务工作的重要环节,涉及大量数据录入、验证与归档,传统方式不仅耗时费力,还容易出错。如何利用先进的AI技术高效且准确地处理海量发票,成为了行业关注的重点。当前,围绕发票信息提取,出现了两种主要策略:基于多模态能力的直接图像分析和基于文本解析的结构化转换。近期一项针对三类多模态大型语言模型的对比评测,集中展示了这两种策略在零样本提示下的性能表现,揭示了不同模型家族及发票类型对结果的影响,为发票自动化处理提供了新思路。多模态处理策略,即模型直接接收发票图像作为输入,利用视觉与语言综合理解能力同步解析图像内容。
如GPT-5、Gemini 2.5和开源的Gemma 3等先进模型,能够结合文字、布局及图像特征,在不依赖预先文本提取的条件下,直观且高效地识别关键财务信息。这种方法能灵活捕捉图像中的复杂元素和结构,尤其适合多样化且格式不统一的发票场景。相比之下,文本解析策略则依赖于先将发票转换为结构化文本格式,如Markdown,然后由语言模型对该文本进行语义理解和数据抽取。这种流程相对传统,框架明确,易于实现标准化处理,适合对文本信息有较强依赖的系统环境。然而,文本转换环节可能导致信息丢失或格式错乱,影响最终解析质量。通过对三类多模态模型的八个实例进行测试,研究成果显著表明在大多数情况下,直接图像多模态处理策略优于文本解析方式。
尤其是在面对复杂布局、多语言和非标准格式发票时,模型的原生视觉能力更具优势。这说明多模态方法能够更准确地捕捉发票中的隐含信息,提高关键字段识别的准确率与完整性。不同模型家族之间的表现存在一定差异,部分开源模型在资源受限环境下表现依然出色,为行业提供了经济高效的解决方案。同时,结合零样本提示技术,用户无需专门训练或数据标注,显著降低了系统部署门槛和维护成本。然而,评测也揭示出图像处理策略在某些极端情况下可能面临解析瓶颈,例如极度低质扫描件或图像噪声过多,这时辅以文本解析步骤或辅助预处理仍然有助于提高鲁棒性。整体来看,多模态与文本基线策略各有千秋,最佳实践应结合实际业务需求、发票多样性和系统资源综合考量。
未来,随着多模态模型架构的进一步优化以及更大规模训练数据的引入,预计其在发票自动化领域的应用将更加深入和普及。企业可借助这类先进模型实现从手动录入向智能识别的转变,提升财务处理效率,降低人工错误风险,同时增强合规性管理能力。同时,开源多模态模型的优势使更多中小型企业具备了引入智能发票处理系统的条件,推动整个行业数字化转型向前迈进。除了技术性能外,发票自动化还需关注数据隐私保护和模型公平性,确保信息安全和合规操作。结合安全加密、权限控制和透明审计机制,可以构建更加可信赖的发票处理平台。作为新兴趋势,多模态与文本解析策略的融合应用也值得期待。
利用多模态模型的视觉优势和文本模型的语言理解能力,构建多阶段、多任务的联合系统,将进一步提升解析的准确性和稳定性。总之,多模态大型语言模型在发票处理中的广泛应用,正在彻底改变传统账单处理模式。通过系统化的性能基准测试与对比分析,企业能够更科学地选择适合自身需求的技术方案,推动财务自动化和智能化迈向新高度。在未来,伴随模型能力不断提升和应用场景不断扩展,发票处理有望实现真正的无人化、智能化管理,极大地释放人力资源,提高运营效率,助力数字经济蓬勃发展。 。