AMD的Zen 5架构是Zen家族的最新演进版本,作为继Zen 4之后的新一代中央处理器核心架构,它在设计上进行了多项优化和重构,尤其在执行引擎的重排序能力以及管线深度和宽度方面实现了加码,从而显著提升了整体处理性能。尽管在SPEC CPU2017等标准生产力测试中,Zen 5表现出色,获得明显性能提升,但在游戏负载中的表现却引发了激烈讨论,尤其是非X3D版本的Zen 5并未在游戏中展现出同等幅度的性能跃升,成为技术评测界关注的焦点。 游戏与传统生产力应用在CPU负载特性上存在显著差异。游戏负载通常属于低指令每周期(IPC)的工作类型,代码中存在较多分支和跳转,并且数据访问的局部性差,导致处理器难以高效利用宽度和深度皆提升的核心资源。Zen 5在测试中显示出前端(Frontend)管线存在较为明显的瓶颈,影响了真实游戏帧率的提升空间。具体来看,Zen 5的前端命名/分配(Rename/Allocate)阶段表现为流水线中最窄的瓶颈,造成指令流的堵塞,后续执行单元难以发挥最大潜力。
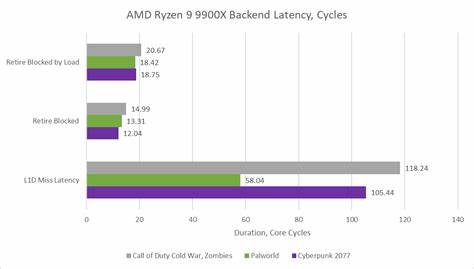
为了深入探讨Zen 5对游戏负载的适应情况,测试团队在相对一致的硬件环境下,替换了处理器并保持其他组件不变,选用了Ryzen 9 9900X搭配DDR5-5600规格的内存,并配备Radeon RX 9070显卡。测试游戏包含目前热门且机制复杂的《Palworld》,《使命召唤:黑色行动冷战》(COD Cold War),以及《赛博朋克2077》(Cyberpunk 2077)。虽然环境和场景有所变动,数据不可直接横向对比,但采用这种方法为观察游戏负载在Zen 5上的整体表现趋势提供了有效视角。 在微架构层面,Zen 5的前端设计融合了一个容量达6000条指令的操作缓存(Op Cache)和32KB的传统一级指令缓存(L1i)。相比上一代Zen 4的5200条指令容量,操作缓存显著扩大。此设计意在加快指令提取速度,降低访问主缓存时的延迟,并提升指令流的持续性。
尽管提升了命中率,实际测试表明,Zen 5的操作缓存平均吞吐率约为每周期6微操作数,尚未达到理论峰值12微操作数。这种差距部分源自指令流中频繁出现的分支影响,分支频率高会限制宽指令提取的收益。 此外,Zen 5引入了分离式的分支预测器,内置大规模的24000条目标缓冲器(BTB),旨在缓解一级指令缓存未命中的影响并提升指令跳转预判的准确性。虽然在SPEC CPU2017等测试中,Zen 5的分支预测准确率优于前代,但在实际游戏负载中,分支预测准确率略逊于竞争对手Intel的Lion Cove架构。这种差异部分源于游戏代码复杂的分支跳转模式和动态性,导致预测失误率增高,进而造成流水线清空和重新装填,从而加剧前端延迟。 不仅如此,Zen 5在处理分支发现阶段出现的“解码器重定向”情况较多,即首次识别某条分支时需要刷新前端指令流,这种行为虽能减少错误投机执行带来的资源浪费,但同样增加了指令流断裂和缓存错失的概率。
Intel相对应的“BAClear”机制较少,显示出其在指令预取以及分支预测协调上的相对优势。显然,前端的结构限制与分支频繁性共同导致Zen 5在实际游戏场景中前端长时间处于闲置等待状态,降低了整体有效指令发放率。 前端的瓶颈不只耗时,也表现为管线中约11到12个周期的指令提取延迟,基本接近L2缓存访问延迟水平,这也侧面说明部分指令需要从L2缓存甚至更高层级缓存中加载,进而影响流程连贯性。尽管Zen 5的1MB L2缓存表现出较高命中率,能有效抵消部分一级缓存失效造成的性能打击,但偶尔仍有延迟较高的L3及DRAM访问穿插其中,增大负载响应延迟。 后端(Backend)阶段,Zen 5核心的设计亮点在于其大规模统一调度器和448条指令容量丰富的重排序缓冲区(ROB)。这使得核心具备一定的指令并行和乱序执行能力,用以隐藏或缓解内存访问带来的高延迟影响。
不过,在游戏负载中,后端仍会因缓存未命中和内存访问延迟而阻塞,尤其是未完成的加载指令占据退休(Retire)阶段时,导致流水线积压。平均每条未完成加载指令的阻塞时间在18到20周期间,显著高于其他指令,说明游戏复杂数据访问模式对内存系统带来严峻挑战。 具体分析游戏测试数据中,内存子系统表现出差异化特征。在《Palworld》中,Zen 5遭遇较多一级数据缓存(L1d)未命中,但较大比例能被L2缓存补偿,降低整体延迟;而《COD Cold War》和《赛博朋克2077》则显示出较高的L1d未命中延迟,提示缓存层次负载压力有所不同。对比Intel的Arrow Lake架构,Intel的192KB L1.5d缓存有效弥补了部分L1d未命中延迟,维持较低整体内存访问时延,体现其在缓存层次设计上的优势和差异化策略。 多核和多集群设计同样影响游戏性能表现。
Zen 5基于双CCX(核心复合体)模块构建,存在跨CCX访问缓存时延较高的问题,但实测发现大部分游戏负载大多集中于单一CCX内,跨CCX访问较少,减小了多核心并发执行时的延迟瓶颈。对比测试中,通过强制将游戏进程线程绑定分布在两个CCX上,导致性能下降约7%,体现跨CCX缓存访问开销真实存在。在现实使用场景下,操作系统和调度器通常会优先调度至单一快速CCX,最大化同一模块内缓存复用和低延迟优势。 Zen 5的这种核心设计相较于Intel的核心,则展现出两家厂商对性能瓶颈侧重点不同的理解和技术侧重。Intel架构相对受后端内存延迟影响较大,而AMD则更多受制于前端指令流供应。未来性能提升的突破口也因而存在差异。
Zen 5及致力于下一代Zen 6的研发,可能会重点解决前端指令缓存和分支预测的未竟之功,同时优化管线内部数字逻辑,提升指令发放速率。Intel则可能继续向缓存层次深度优化以及执行引擎的并行度发力。 游戏作为一种典型的低IPC和复杂分支密集型负载,对CPU的设计提出了多面挑战。从指令调度、分支预测到缓存系统,每一环节都须权衡功耗、延迟与吞吐量。对于Zen 5而言,尽管其宽度和深度都较上一代实现了攀升,但现实中的游戏表现得益有限,凸显了游戏负载对处理器整体架构灵活性的独特需求。 展望未来,AMD可以在保持核心宽度的同时,加大在前端缓冲能力和分支预测准确性上的投入。
例如,进一步扩充操作缓存容量、改进指令解码效率和实现更智能的分支动态调整机制。同时,结合低延迟的缓存层次体系,提升内存访问速度,尤其是跨CCX的数据访问效率,将成为关键改进方向。更重要的是,针对游戏这样难以充分利用高IPC的工作负载,优化核心对低IPC代码序列的容错与预测能力,将有助于实现真实游戏性能的大幅提升。 总结来看,AMD Zen 5架构在生产力应用中大显身手,但在游戏负载中受限于前端指令流供应和缓存层次系统的复杂表现,未能充分发挥其宽深管线的潜力。多核心调度与缓存聚合性能尚需精细调优,以避免跨CCX访问带来的显著性能损失。整体而言,Zen 5为AMD CPU架构带来了新思路与新技术基础,而这些将在未来迭代中形成更为全面平衡的性能表现。
针对游戏负载全面提升的愿景,也意味着AMD未来要在前端优化、缓存设计和调度策略上做出持续创新,为广大游戏玩家带来更流畅、更高效的游戏体验。