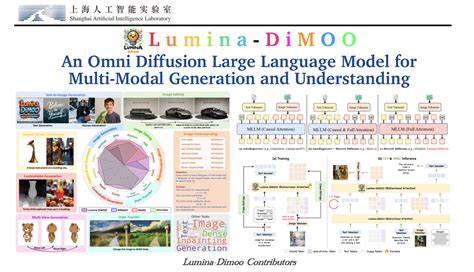
随着人工智能技术的日新月异,多模态模型的研究与应用正逐渐成为智能产业发展和创新的核心驱动力。多模态模型能够同时处理和理解文本、图像、音频等多种信息形式,为智能系统的感知与交互能力赋能。近日,由上海人工智能实验室及多所高校联合推出的Lumina-DiMOO模型备受关注,它以开源的姿态和创新的离散扩散方法,为多模态生成与理解带来了全新突破。 Lumina-DiMOO是一款基于离散扩散机制的多模态基础模型,旨在实现输入输出形式的高度统一和高效采样。传统多模态模型往往依赖自回归(AR)或混合AR扩散机制,在处理速度与多样化任务支持方面存在一定瓶颈。相比之下,Lumina-DiMOO通过全离散扩散理念将不同模态转化为统一的离散表示,极大提升了采样效率,且能够无缝支持文本生成图像、图像到图像的编辑与再创造、主题驱动生成以及图像内容理解等丰富场景。
在文本生成图像领域,Lumina-DiMOO可以精准捕捉自然语言描述的细节,生成高质量且逼真的图像。模型对于复杂场景如光影变化、质感描绘、物体排列关系等呈现出显著优势,且能够根据具体需求进行风格化风格迁移和内容细化。例如,模型能够根据文本描述模拟光滑的橙汁溅出形成特定字体的动态效果,或者根据美食介绍生成口感细腻、色彩协调的甜点图像,充分展现了理解与创造的深度融合。 图像编辑和主题驱动生成是Lumina-DiMOO另一大亮点。用户可通过添加、移除或替换图像中特定元素,实现风格转换、场景扩展或细节修饰。无论是将普通墙面替换为砖墙,还是用蝴蝶替代图像中特定鸟类,模型都能在保持整体视觉连贯性的同时,精准完成用户所需。
尤其在主角驱动生成方面,Lumina-DiMOO能够灵活捕捉主体的独特特征并迁移至新场景,满足创作多样性和个性化需求。 图像理解能力是多模态AI不可或缺的组成部分。Lumina-DiMOO通过整合视觉和语言处理技术,能对复杂图像进行全方位解析。无论是描述场景,还是识别物体关系,模型表现出高度准确性和细节把握能力。在多项权威基准测试中,Lumina-DiMOO均获得领先成绩,超越了大量现有同类开源模型,展现了其卓越的技术实力和广泛适用性。 技术实现上,Lumina-DiMOO依托于离散扩散过程,将图像和文本等多模态信息映射到统一的离散编码空间,利用扩散模型的渐进式生成优势,实现对多模态内容的高效采样和精准生成。
该模型参数规模控制在适中范围内(约8亿),兼顾性能与计算资源需求。开发团队采用MindSpeed MM开源训练框架,充分发挥华为Ascend AI芯片的分布式计算能力,保证模型训练的高效性和可扩展性。 Lumina-DiMOO的开源发布不仅丰富了多模态扩散模型领域的技术生态,同时也促进科研与工业应用的融合发展。开发者和研究人员可以基于该模型开展多模态生成、智能编辑和视觉理解的深入探索,推动生成艺术、智能助手、自动内容创作、虚拟现实等多个方向的突破。开源的代码与模型权重为社区创新提供了坚实基础,实现了技术共享和应用共赢。 从评测数据看,Lumina-DiMOO在GenEval、DPG和图像理解等多套基准测试中表现优异。
它在单对象及多对象生成准确率、属性关系识别、场景理解与上下文推理等方面均达到领先水平。数值指标显示其生成质量、语义理解力和任务泛化能力优于当前众多知名模型,体现了其在多模态智能领域的竞争力和潜力。 此外,Lumina-DiMOO还在实际应用演示中展示出丰富的功能示例。从复杂文本描述绘制逼真图像,到细致的图像风格化和编辑,再到交互式主题迁移与场景补全,模型完美诠释了多模态AI技术服务创意表达的无限可能。它不仅满足艺术创作的个性需求,也助力工业设计、媒体制作、教育培训等多个行业迈向智能化转型。 总体而言,Lumina-DiMOO作为一款基于离散扩散的多模态大模型,以其创新的技术路径、高效的运算机制和多功能集成能力,推动了多模态AI从理论到实践的跨越。
它不仅弥合了多模态输入输出的鸿沟,还实现了生成速度与质量的双重提升,开启了更加广阔的智能感知与表达新时代。未来,随着社区持续优化和新应用场景的挖掘,Lumina-DiMOO有望引领多模态人工智能走向更高水平的普及与智能化。 通过开源精神,Lumina-DiMOO不仅推动了技术创新,也为全球AI研究者提供了宝贵资源,预示着人工智能结合视觉与语言理解协同发展的光明前景。无论是学术研究者还是产品开发者,都可以依托该平台开启多模态智能的探索之旅,助力实现更加丰富、多元和智能的数字世界交互体验。 。